 クリプ犬のメディア
クリプ犬のメディア 

皆さんは仮想通貨調べる際、どのように調査していますか?
ググるくらいしか私分かんなくて…。

確かに、自分も最初の方はググるとかSNSを見るとかしか分からなかったな。
でもググった先のサイトとか、分かりやすいの多いからいいんじゃないかな。
でも、サイトによっては記載していることが違ったり、逆に多いのはほとんど同じ内容書かれていたり、参考にしがたい時があるの…。
自分で根拠のあるものをみて納得したいんだよね~。
事務員さんも成長したなぁ~(笑)
確かに投資するならなおさら根拠あるものを見たいよね。
そんな時はホワイトペーパーを見てみるといいよ◎
ホワイトペーパーってなになに??
ホワイトぺーパーとは?
ホワイトペーパーとはその仮想通貨の開発された目的や技術について、今後の計画などが記載された報告書のようなものです。
ほとんどの仮想通貨にはホワイトペーパーは必ず用意されており、信頼できる報告書です。
気になる仮想通貨がある場合は、必ずホワイトペーパーを見るようにしましょう。
より詳しくはこちらの記事にて記載しておりますので、ぜひご参照ください。
ただ、ホワイトペーパーは全て英語で書かれていたり、技術の事ばかりで何書いているか分からないことも多いです…。
そこで、当サイトでは、仮想通貨毎のホワイトペーパーから読み取れた内容などを用いて今後の予想などしていきます。
ぜひ参考にしていってください◎
目次
結論|今後の予想
1.「確認ポイント」
1-1.ロードマップ(開発スケジュール)
1-2.発行主体(プロジェクトメンバー)
1-3.拠点
1-4.資金調達方法・使い道
1-5.開発目的(具体性があるか)
1-6.発行上限
2.「ホワイトペーパー」
2-1.日本語訳
2-2.原文
結論|今後の予想
まず今後の予想から記載します。
結論:今回の分析だと、今後も安心して投資できそうと判断しました。
安心度合い:
過去最高価格はローンチ直後の約112円ほどでしたが、現在は30円ほど(2023/06/21現在)
最近マイクロソフトがAIを研究する会社(OpenAI)に100億ドルもの投資をするというニュースを受け、8円⇒83円までの高騰を見せました。(1000%以上の高騰)
さらに、ホワイトペーパーやホームページもしっかり記載されているので安心できそうです。
【良い点】
・業務提携先企業が名前も含めて公開、記載されている点
・開発メンバーがまとめられ分かりやすく記載されている点
・ロードマップが細かい粒度で記載されており、進捗の把握が簡単に出来る点
【懸念点】
・ロードマップが細かいのはありがたいですが、全体を俯瞰したロードマップも気になりました。

よろしければご利用ください。

仮想通貨AGIXとは?
AGIXは一言で言うと、ブロックチェーンを用いたAI統合プラットフォームの実現を目指しています。
世界各地、各企業で様々なAIが登場、使用されていますが、各AIの経験値は各AI固有のものとなっています。
その経験値をAGIXのプラットフォーム上でAIを作成、使用していれば、経験値を共有出来たり、他の複数のAIとを組み合わせることが可能になるため、AIの相乗効果を生み出せるのでは?という考えを実現すべく、生まれたプラットフォームです。
【特徴】
● SingularityNETのネットワークは複数のブロックチェーンと相互運用できるようになるとのこと。
●各個人のデータの主権はユーザー側が握っているとのこと。
● SingularityNETは個人契約と公的契約の両方を安全にホストするため、よりスケーラブルで弾力性のあるアプリケーションをほぼゼロの取引コストで構築することができるとのこと。
簡単に特徴を掴めたところで、ホワイトペーパーの分析に進みましょう。
1.「ホワイトペーパー 確認ポイント」
まず以下の図をご覧ください。
ホワイトペーパーから読み取るべきポイントを簡単にまとめたものです。
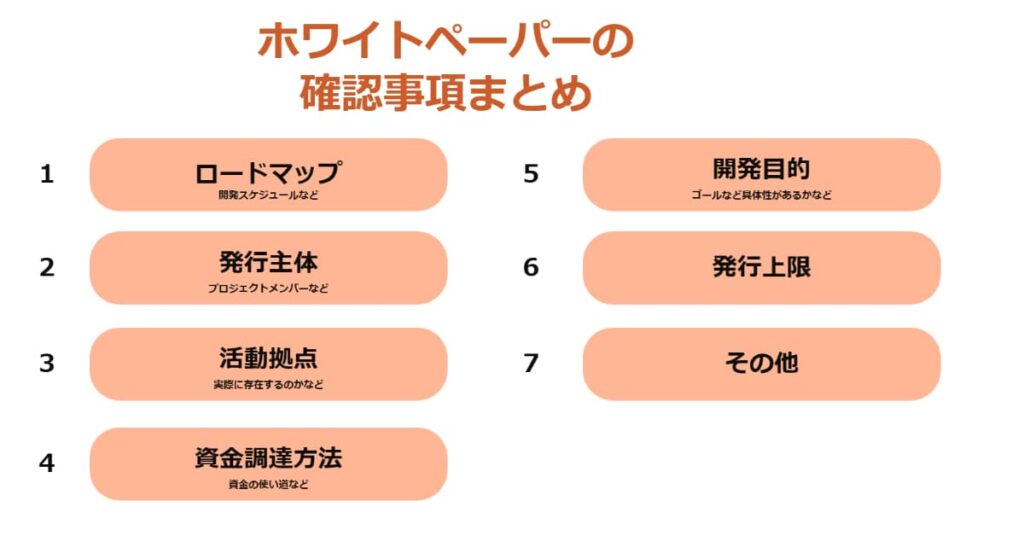
ホワイトペーパーからはひとまず、発行上限までの6つの事項が確認できるかチェックしましょう。
仮想通貨は信用できる情報をどれだけ早く正確に手に入れられるかが大事です。
チェック項目を絞っておくことで、少しでも他の方より一歩先へ行けるよう準備しておきましょう。
ただ、ホワイトペーパーの中には、技術的側面が多く記載されたホワイトペーパーや、記載情報が少ないものもあります。
そこで、上記の6つの項目がホワイトペーパーに記載されているかの有無と、無かった場合の簡易的な検索結果をまとめましたので、ぜひご活用下さい。
1-1.ロードマップ(開発スケジュール)|AGIXとは
ロードマップとは、丁寧に一言で表すと、「(ある仮想通貨の)今後の計画を記したもの」です。

ホワイトペーパ―の中で、その仮想通貨の今後または現在の進捗具合を知るのに、ロードマップは大きな役割を果たします。このロードマップが細かく書かれている方が投資家にとっても投資対象かどうか判断しやすいですし、綿密な計画を練っている事も判断できるので、ロードマップの粒度も確認したいポイントです。
【AGIX ロードマップ】:
ホワイトペーパーからは見つけられませんでした。
【検索結果】:
公式ホームページに記載がありました。
開発などが分かりやすい単位で分けられており、「2023年第一四半期には~をする」といったように何をいつしているのか明確になっていました。また、進捗などをブログやYoutubeでも確認することができ、親切ですね。
1-2.発行主体(プロジェクトメンバー)|AGIX 開発メンバー

発行主体は見落としがちですが、しっかり確認しましょう。
時価総額が高くETHのように有名であれば、発行元が不明瞭なことはあり得ませんが、念のためどのホワイトペーパーでも確認するようにしましょう。
【AGIX 発行元】:
ホワイトペーパーに記載はありませんでした。
【検索結果】:
創立のメンバーやExecutiveメンバーが以下のように画像や紹介のURLが載っていました。
こちらも分かりやすく親切ですね。

1-3.活動拠点(実際に存在するかも併せて)|AGIX 仮想通貨

開発拠点・活動拠点がしっかり記載してあれば、信用度は上がります。
ただこれからはより非中央集権化が進むと思われるため、活動拠点がしっかりとしているものも少なくなってくるかもしれません。あれば本当に存在しているのか確認してみましょう。
【AGIX 活動拠点】:
ホワイトペーパーからは見つけられませんでした。
【検索結果】:
検索しても開発拠点などの記載は見つけられませんでした。
1-4.資金調達方法(資金の使い方も併せて)|AGIX ホワイトペーパー

資金の有無はその仮想通貨の将来性にも大きく関わってきます。
資金調達がしっかり公表されており、資金調達した企業が大物であればあるほど世間からの期待は大きいものとなり、価格もそれに比例するものです。
資金調達とは少し話がずれますが、かのイーロンマスクがドージコインに投資をするようなツイートをしたところ、とんでもない高騰を見せました。
たまたま買っていた方羨ましい…。(笑)
【AGIX 資金調達方法】:
AGIXの資金調達方法に関しての記載は、ホワイトペーパーに以下のような記載がありました。
また、ホームページにも提携企業が複数記載がありました。
資金額は不明ですが、有名企業が集まっていたので、少し期待できますね…。
・SingularityNET財団は、2017年末から2018年初めにかけて、以下の主要なグループによって結成されました。
● オープンソースの人工知能プラットフォーム「OpenCog」を運営するOpenCog Foundation
● 世界で最もリアルな人型ロボットを開発したHanson Robotics社
● Vulpem社:ブロックチェーンソフトウェアエンジニアリングコンサルタント会社で、設計に成功した多くの プライベートおよびパブリックブロックチェーン、暗号通貨、分散型アプリケーションのバックエンド作業を担当 している。
● 2001年から企業や政府機関にカスタムAIソリューションを提供している人工知能ソフトウェアコンサルタント会社Novamente LLC社
1-5.開発目的(具体性のあるものかどうか)|仮想通貨 AGIX 将来性

開発目的がはっきりしていない仮想通貨は将来性ははっきりいってありません。
もしあなたが本気でどこかの株を買う際、何のためにその会社が存在しているのか調べたりしますよね。
その会社が目的を持たずふんわりやっていそうだなと判断した時投資するでしょうか?
私ならしません…。
ただ、ホワイトペーパーに開発目的が書かれていないからといって将来性が無いとは言い切れません。
ホワイトペーパーが技術に関してを中心に書かれているものも多いためです。
【AGIX 開発目的】:
以下の記載がありました。
・SingularityNETの主要な目標は、技術が人間の基準から見て善良であることを保証し、ネットワークが有益な プレーヤーにインセンティブを与え、報酬を与えるように設計されていることである。
・SingularityNETが、垂直市場全体で優れたAIアプリケーションを育成し、強力で慈悲深い人工一般知能を播種するという目標
・私たちの目標の一つは、より高性能でより知的なAIサービスの開発を導くために、複雑な創発現象を測定するための新たなツールを作り出すことです
1-6.発行上限|仮想通貨 AGIX 価格

発行上限はその仮想通貨の価格に大きく影響を及ぼします。
極論を言ってしまうと、もし無限に発行されるものの場合、価格はどこまでも落ちる可能性があります。
上限がきちんと制定されているモノの方が筆者は安心いたします。
【AGIX 発行上限】:
ホワイトペーパーからは見つけられませんでした。
【検索結果】:
最新のcoinmarketcapによると最大供給量が20億枚になっていました。
2.「ホワイトペーパー」
以下では原文のリンクと日本語訳を記載しておりますので是非ご活用ください。
2-1. AGIX ホワイトペーパー 原文
2-2. AGIX ホワイトペーパー 日本語訳
※翻訳時期:2022/11/05
※Deepl Proを中心に適宜修正を加え、翻訳したものですので正しいとは限りませんのでご注意下さい。
※ページ数が158もあったため図などは今回省略しました。
8 シンギュラリティネット
ホワイトペーパー2.0
1
シンギュラリティネット
AIのための分散型オープンマーケットとネットワーク ホワイトペーパー2.2019年2月
概要
人工知能は年々その価値を高め、強力になっており、やがてインターネットを支配するようになるだろう。Vernor VingeやRay Kurzweilなどのビジョナリーは、今世紀中に「技術的特異点」が発生すると予言しています。SingularityNETプラットフォームは、ブロックチェーンとAIを一緒にして、新しいAIファブリックを作り、今日、優れた実用的なAI機能を提供しながら、シンギュラリティの人工総合知能ビジョンの実現に向けて進んでいます。
今日のAIツールは、閉ざされた開発環境によって断片化されています。ほとんどが1つの企業によって開発され、1つの極めて狭いタスクを実行するもので、2つのツールを接続する簡単で標準的な方法は存在しません。SingularityNETは、AIと機械学習ツールをネットワーク化し、垂直市場全体で非常に効果的なアプリケーションを形成し、最終的に協調的な人工的な一般知能を生成するための主要プロトコルになることを目指します。
今日のAI研究の大半は、開発資金を持つ一握りの企業によってコントロールされています。独立したAIツールの開発者は、開発したツールを収益化する手段がない。通常、最も有利な選択肢は、大手ハイテク企業のいずれかにツールを売却することであり、技術の支配がさらに集中することになる。SingularityNETのオープンソースプロトコルとスマートコントラクトのコレクションは、このような問題に対処するために設計されています。開発者は自分のAIツールをネットワーク上で公開し、他のAIや有料ユーザーと相互運用することができる。
SingularityNETのプラットフォームは、アプリストアがモバイルアプリ開発者に市場参入の道を提供するように、開発者に商業的な出発点を与えるだけでなく、AIが相互運用することで、より相乗的で幅広い能力を持つインテリジェンスを生み出すことができます。例えば、音声合成AIとイタリア語から英語への翻訳AIがネットワーク上に存在する場合、ネットワーク全体として、イタリア語のテキストを使って英語の音声を生成することができるようになるのです。
この枠組みでは、AIは企業の資産からグローバルコモンズへと変化し、誰もがAI技術にアクセスしたり、その開発のステークホルダーとなることができます。また、誰でもAI/機械学習サービスをSingularityNETに追加し、ネットワークで利用することができ、その対価としてネットワーク決済用トークンを受け取ることができます。
SingularityNETはSingularityNET財団(1.5節で説明)の支援を受け、AIの恩恵は一部の強力な機関だけにもたらされるべきでなく、むしろすべての人が共有すべきであると考えています。SingularityNETの主要な目標は、技術が人間の基準から見て善良であることを保証し、ネットワークが有益なプレーヤーにインセンティブを与え、報酬を与えるように設計されていることである。このことは、このプロジェクトが、短期的な実用的・商業的目標に加え、以下のようなプロジェクトの立ち上げに中心的な役割を果たすことを明確に目指していることを考えると、非常に重要である。
VingeやKurzweilなどが予見した技術的特異点、すなわち自己修正、自己改善、自己理解のできる人工知能の出現と経済的普及を触媒として。
シンギュラリティネットのプラットフォーム、AIネットワーク、エコシステムは現在進行中であり、今後もそうであることを意図しています。この精神に基づき、あなたが読んでいるものは、SingularityNETの最初のホワイトペーパーを大幅に改訂したものです。最初のバージョンは、ネットワークの最初のトークン生成イベントの前の2017年秋に書かれましたが、このバージョンは2019年2月に書かれ、その間に学び、構築されたものを反映したものです。
内容
ビジョン ……………………………………………………………………………………………………………………. 6
1.1 インスピレーション …………………………………………………………………………………………… 6
1.2 急成長する市場のニーズに応える ……………………………………………………………………… 7
1.3 堅牢で適応性の高いソフトウェア・アーキテクチャ …………………………………………. 9
1.4 分散型自己組織化協同組合 ………………………………………………………………………………. 10
1.5 シンギュラリティNET財団 ………………………………………………………………………………. 12
シンギュラリティネット・プラットフォーム …………………………………………………………. 13
2.1 SingularityNETベータ版プラットフォームの概要 …………………………………………….. 13
2.2 SingularityNETデーモンとラッピングサービス ………………………………………………… 15
2.3 シンギュラリティNETレジストリ ……………………………………………………………………. 17
2.4 マルチパーティーエスクローとチャネルによるスケーラブルな支払い …………… 18
2.5 マーケットプレイスDApp ………………………………………………………………………………… 20
2.5.1 サービス一覧 ……………………………………………………………………………………………. 20
2.5.2 サービスの実行 ………………………………………………………………………………………… 21
2.6 開発者支援ツール。CLIとSDK ………………………………………………………………………… 22
2.6.1 サービスプロバイダー向けコマンドラインインターフェース …………………. 22
2.6.1.1 CLIの仕組み …………………………………………………………………………………….. 23
2.6.1.2 サービス登録・展開のワークフロー ………………………………………………… 24
2.6.2 サービス・コンシューマー向けソフトウェア開発キット ………………………… 24
2.7 今後の改善点 ……………………………………………………………………………………………………. 25
2.7.1 複雑なサービスの相互作用サービスオントロジーとAPI of API ………………. 26
2.8 レピュテーションシステム ………………………………………………………………………………. 27
2.8.1 レピュテーションシステムコンセプト …………………………………………………….. 29
2.8.2 レピュテーションシステムオプション …………………………………………………….. 29
2.8.3 レピュテーション「Liquid Rank」アルゴリズム ………………………………………. 30
2.8.4 レピュテーションポリス ………………………………………………………………………….. 30
2.9 AI インフラストラクチャー・アズ・ア・サービス ………………………………………….. 31
2.10 ロボット・組込み機器への展開 ……………………………………………………………………… 32
2.11 ブロックチェーン不可知論 …………………………………………………………………………….. 32
2.11.1 評判に基づくコンセンサス …………………………………………………………………….. 33
2.12 現行コンポーネントのインクリメンタルな改善 ……………………………………………. 33
民主的ガバナンス ……………………………………………………………………………………………………. 34
3.1 評判と利害関係者の投票 ………………………………………………………………………………….. 34
3.2 完全な民主主義への移行 ………………………………………………………………………………….. 36
3.3 ベネフィット・タスクに関する決定事項 …………………………………………………………. 36
4.ハイレベルAIサービス……………………………………………………………37
4.1 まとめ ……………………………………………………………………………………………………………..38
4.1.1 AIソリューションの必要性 ……………………………………………………………………………….38
4.1.2 AI サービスとは?…………………………………………….39
4.1.3 高次AIサービスが成長を牽引する ………………………………………………………………40
4.2 SingularityNET Foundation が提供する AI サービス………………………………………………………………..41
4.2.1 ネットワーク分析 ……………………………………………………………………………………….41
4.2.1.1 動機 …………………………………………………………………………41
4.2.1.2 用途例 ………………………………………………………..42
4.2.1.3 SingularityNETシミュレーション …………………………………………………………43
4.2.1.3.1 ソーシャルメディア ……………………………………………………………………………………………….44
4.2.2 ソーシャルロボティクス …………………………………………………………………………………………….45
4.2.2.1 モチベーション ……………………………………………………………………………….. 45
4.2.2.2 応用例 ………………………………………………………………………………………………. 46
4.2.2.3 計画 ………………………………………………………………………………………………….. 46
4.2.2.4 サービス …………………………………………………………………………………………… 46
4.2.2.5 マインド・モデリングとラビングAI開発 ……………………………………….. 48
4.2.2.6 ディープ・リカレント・ニューラル・ネットワークによる社会認識 . 48
4.2.3 バイオデータ解析 …………………………………………………………………………………….. 49
4.2.3.1 モチベーション ………………………………………………………………………………… 49
4.2.3.2 応用例 ………………………………………………………………………………………………. 49
4.2.3.3 サービス …………………………………………………………………………………………… 52
4.2.4 確率的グラフィカルモデルとシリアスゲーム ………………………………………….. 54
SingularityNET AI研究開発の概要 ………………………………………………………………………….. 54
5.1 はじめに …………………………………………………………………………………………………………… 55
5.2 AIアーキテクチャとアルゴリズム …………………………………………………………………… 56
5.2.1 記号的学習と推論 …………………………………………………………………………………….. 56
5.2.1.1 スケーラブルな一般確率論理学 ……………………………………………………….. 57
5.2.1.2 確率的進化プログラムの学習と推論の統合.58
5.2.1.3 論理的ハイパーグラフにおけるパターンマイニング ……………………….. 59
5.2.1.4 非線形な注意の割り当てによる推論の誘導 ……………………………………… 59
5.2.2 統合AIの事例としての統合ゲノミクス …………………………………………………….. 60
5.2.3 セマンティックコンピュータビジョンのための神経-シンボリック統合 ….. 61
5.2.3.1 視覚的推論 ……………………………………………………………………………………….. 62
5.2.3.2 概念と表象の学習 …………………………………………………………………………….. 63
5.2.3.3 ディープニューラルネットワークにおける汎化・不変性 ………………… 64
5.2.3.4 神経-シンボリック統合のためのフレームワーク …………………………….. 64
5.2.4 教師なし言語学習 …………………………………………………………………………………….. 65
5.2.4.1 教師なし文法学習へのアプローチ ……………………………………………………. 66
5.2.4.2 確率的言語生成 ………………………………………………………………………………… 67
5.2.5 言語から論理への写像の半教師付き学習 …………………………………………………. 67
5.2.5.1 ルール学習 ……………………………………………………………………………………….. 68
5.2.5.2 自然言語生成の支援 …………………………………………………………………………. 69
5.2.5.3 複雑な言語構造へのスケーリング ……………………………………………………. 69
5.2.6 ゴール駆動型対話システム ………………………………………………………………………. 70
5.2.6.1 意図的な分類 ……………………………………………………………………………………. 71
5.2.6.2 対話の表現と状態の追跡 ………………………………………………………………….. 71
5.2.6.3 オーサリング/開発用インターフェイス ……………………………………………. 71
5.2.7 セマンティックハイパーグラフのための分散処理 …………………………………… 72
5.2.7.1 分散型AtomSpace×分散型データベース ……………………………………………. 72
5.2.7.2 分散型DBMSの拡張………………………………………………………………………….. 73
SingularityNETの測定、モデル化、拡張…………………………………………………………………. 74
6.1 記号的相互作用に基づく複雑ネットワークシミュレーションモデリング ……….. 75
6.1.1 模擬ネットワークにおけるエージェント選択 ………………………………………….. 76
6.1.1.1 SISTERシステムにおけるAIエージェントサイン …………………………….. 77
6.1.2 ソーシャルアルゴリズムで社会問題を解決する ………………………………………. 78
6.2 複雑な認知ネットワークにおける統合情報計測のためのTononi Phi ………………… 79
6.2.1 チューニングパラメーター ………………………………………………………………………. 80
6.2.1.1 AIシステムにおける認知的尺度の定量化 ………………………………………….. 80
6.2.2 特異なSingularityNETサービスに対する影響 ……………………………………………. 81
6.3 エージェントシステムにおける複雑な交換パターンを最適化するオファーネットワーク………………………………………………………………………………………………………………….. 82
6.3.1 分散型コンピューティング ………………………………………………………………………. 82
6.3.2 シミュレーションエンジン ………………………………………………………………………. 83
6.3.3 監視・分析エンジン …………………………………………………………………………………. 83
6.3.4 オファーネッツ エコノミー ……………………………………………………………………… 83
6.3.5 SingularityNETの主要ネットワークへの統合 ……………………………………………. 84
乳幼児期から児童期、そしてその後までネットワークを導く ……………………………….. 85
ビジョン
1.1 インスピレーション
技術的特異点(シンギュラリティ)の必然性は、テクノロジーやビジネスの世界全体でますます受け入れられています。知識ある人々は、今後数十年の間に、機械知能が支配的な要素となる新しい社会と経済への移行が起こることを認識している。そのためには、機械的・有機的な知能の群れがネットワークを形成し、前例のない複雑さと高度さ、そして単独では持ち得ないパワーと柔軟性を備えた「グローバル・ブレイン」ダイナミクスを出現させなければならないのです。1
市場には認知的シナジーの要素があり、経済におけるエージェントはそれぞれ比較的単純な目標を追求するが、その相互作用から高次の目標を持つパターンが生まれるのである。SingularityNETは、単なるAIの集合体ではなく、市場なのです。自己組織化する群知能を活用し、部分の総和よりも大きな全体を作り出すように設計されています。ブロックチェーンにより、デジタル環境で経済ルールをプログラムし、AIソフトウェアがシームレスに相互作用することができます。
ポジティブな “グローバル・ブレイン “創出の道は険しい。技術的特異点(シンギュラリティ)は未曾有の利益をもたらす可能性があるが、同時に未曾有のリスクもはらんでいる。一般紙は、人工的な一般知能の危険性についての悲惨な警告に満ちている。
その課題のひとつは、集団行動のための現在のプロトコルである。多くの点で、今日の金融メカニズムや制度は、シンギュラリティへの危険な旅を私たちに強いることになる。より柔軟でオープン、そして迅速に適応できる新しい経済構造とダイナミクスが必要なのです。2
ネイティブなデジタルマネーを持つブロックチェーンは、機械知能が支配する経済において、取引を管理するための強力なツールです。3しかし、ブロックチェーンは単なるツールであり、それをどのように使うかについて重要な決定が必要です。SingularityNETは、AIエージェントが互いに、また外部の顧客とやり取りする際のニーズに応えるために設計された、ブロックチェーンベースのフレームワークです。SingularityNETの中核は、AIエージェントがAI作業の依頼、データ交換、AI作業結果の提供に使用できるスマートコントラクトテンプレートのセットです。
このフレームワークは、脳の各領域がそれぞれの専門性を発揮するように、異質な要素を集合的な知性に結びつけようとするネットワークです。このネットワークは、ポジティブな原則を念頭に置いて設計することが重要です。
● 特定の問題に対する民主的ガバナンス-もしコミュニティがシステムを統治するならば、システムはコミュニティの利益のために行動する傾向がある。
—————————————————–
1Damien Broderick, The Spike (Tor Books, 1997); Ray Kurzweil, The Singularity Is Near (2006); Vernor Vinge, “The Coming Technological Singularity,” Whole Earth Review 81 (1993):88-95; Ben Goertzel, “Human-level
10
Artificial General Intelligence and the Possibility of a Technological Singularity:また、このような技術的特異点(シンギュラリティ)に対して、マクダーモットの批判は、「人工知能 171, no.18 (2007):1161-73.
2ベン・ゲーツェル、テッド・ゲーツェル、ツァラトゥストラ・ゲーツェル、「グローバル・ブレインと豊かさの新興経済。相互主義、オープンコラボレーション、交換ネットワーク、自動化されたコモンズ」Technological Forecasting and Social Change 114C (2016):65-73.2016年、http://goertzel.org/OpenCollaboration.pdf。
3ジョン・クリッパー、デヴィッド・ボリアー『ビットコインからバーニングマン、そしてその後』(オフ・ザ・コモン・ブックス、2014年)。
● 革新的な新しいエージェントのネットワークへの参入を促す奨励と、エージェントが集合知を養うような行動をとるために必要な条件の創造
● ネットワークの努力のかなりの割合を、広く利益をもたらす活動に向けること。
SingularityNETは、これらの要求を満たすために、次のような工夫をしています。
● 企業やその他の組織、個人に対して情報サービスを提供しています。
● ますます強力になる分散型一般知能の出現を促進すること、および
● 人工知能を導入することで、できるだけ多くの人間や知覚を持つ生物に、より大きな利益をもたらすこと。
SingularityNETは、現在非常に価値のあるものであると同時に、最終的には人間レベルを超えた一般的な知能と有益な倫理的特性を持つ、自己修正可能な分散型「人工認知生物」の出現のための基礎を築くように設計されています。これは、人工的な一般知能、4 オープンエンドな知能、5 グローバルブレイン、6 などについて、我々の創設者が長い間理論的に考え、プロトタイプ化してきたことに触発された実用的なデザインである。
1.2 急性期市場ニーズ 対応
SingularityNETは、深刻かつ加速する市場ニーズに応えます。現在の経済的・技術的状況では、あらゆるビジネスがAIを必要としていますが、既製のAIがビジネスのニーズに合致することはほとんどありません。カスタムAIを構築するために開発者を雇えるのは巨大企業だけで、その企業でさえも需要に見合うだけのAI専門家を雇用するのは困難です。SingularityNETは、あらゆるビジネスが既存のAIツールを接続して必要なソリューションを構築できるよう、自動化されたプロセスを提供します。アクセシビリティとカスタマイズ性を最適化し、その性質上、独自開発に伴う労力の重複を減らし、開発をより効率的にします。
最先端のAIツールの多くは、大学院生や独立した研究者によって作成されたGitHubリポジトリにのみ存在します。画像・映像解析、機械翻訳、定理自動証明、バイオインフォマティクスデータ解析などの最新アルゴリズムは、通常Githubで公開されているが、インストール、設定、実行に特有の摩擦があるため、利用が制限されている。多くはデモに過ぎない。AI開発者の多くは学者であり、ビジネスマンではないため、簡単にアクセスできるマーケットを持たず、賢いAIコードをマネタイズすることができません。その結果、実際の製品に搭載されるAIは、数ヶ月から数年遅れで開発される傾向にあります。
—————————————————–
4ベン・ゴアツェル『AGI革命』(Humanity+ Press、2016年)。
5David Weaver Weinbaum and Viktoras Veitas, “Open-ended Intelligence,” in International Conference on Artificial General Intelligence (Springer, 2016):43–52, https://arxiv.org/abs/1505.06366.
6F. Heylighen, “The Global Superorganism: An Evolutionary Cybernetic Model of Emerging Network Society”, Social Evolution and History 6, no.1 (2007).
SingularityNETは、開発者がAIモデルやアルゴリズムを迅速に実世界のアプリケーションに導入するためのローンチパッドです。
また、機械学習ツールには十分な大きさのデータセットが必要です。このような大規模なデータセットを作成・管理することは、ほとんどのAI開発者の手段や能力を超えており、現在普及しているクローズドな開発モデルは、開発者がデータセットを共有することを困難にしています。
図1.主要な障害物が残っている
SingularityNETは、これらのAIツールやデータセットをマーケットプレイスに接続し、エンドユーザーや開発者がアクセスできるようにし、開発者には創作物を収益化する方法を提供します。これは、AIのためのシェアリングエコノミー市場であり、これらのツールがデータや能力を共有することで、AIの恩恵へのアクセスを民主化することを可能にします。
この目標に基づき、SingularityNETはオープンなネットワークとします。SingularityNETのAPIに従って情報を共有し、SingularityNETの経済ロジックに従って支払いを受け払いするAIエージェントであれば、誰でもAIエージェントを挿入することができます。新しいAIエージェントは、SingularityNETのマーケットプレイスへのアクセスを希望するAI開発者や、他のAIと連携してAIエージェントの知能を高めたいと考える開発者から生まれます。
UberやAirbnbのように、未開拓の大きなリソースとそのリソースを必要とする大きな市場を特定し、その2つをつなぐツールを立ち上げています。未開拓のリソースとはGitHubなどにあるAIアルゴリズムやソフトウェアで、市場とはAI専門家のチームを持つ余裕のない99%の企業です。
AirBnBのネットワークにあるアパートが集まってメタ・アパートになるわけでもなく、Uberのネットワークがメタ・カーを生み出すわけでもなく、SingularityNETのネットワークにあるAIが集まってメタAIを形成し、その知能はそれぞれの部分の総和を超えます。前例のない強力なネットワーク効果の組み合わせがここにあり、AIと関連する人間のコミュニティのネットワークが十分な大きさと成熟度に達したときに、その効果が発揮されるのを待っているのです。
1.3 堅牢で適応性の高いソフトウェア アーキテクチャ
コンピュータサイエンス用語で言うと、SingularityNETは、AIや機械学習ツールを使って市場のインタラクションを促進するための新しい種類のスマートコントラクトを作るための分散コンピューティングアーキテクチャである。以下のような設計方針が随所に盛り込まれています。
● 相互運用性。ネットワークは複数のブロックチェーンと相互運用できるようになります。
● データ主権とプライバシーネットワークには、個人データを共有するためのユーザー側のコントロールが含まれています。ユーザーは自分のデータを管理することができ、スマートコントラクトを通じてネットワークと共有することができます。
● モジュール性。柔軟なネットワーク機能により、カスタムトポロジ、任意の複雑さのAIエージェントのコラボレーション、障害回復方法を作成することが可能です。
● スケーラビリティ。SingularityNETは個人契約と公的契約の両方を安全にホストするため、よりスケーラブルで弾力性のあるアプリケーションをほぼゼロの取引コストで構築することができます。
図2.AIエージェント間の認知相乗効果
SingularityNETエージェントは、クラウド上だけでなく、携帯電話やロボット、組み込みデバイスでも動作します。
1.4 分散型自己組織化 協同組合
SingularityNETは、「分散型自己組織化協同組合」と考えることができます。このコンセプトは、よりよく知られている「分散型自律組織」(「DAO」)に似ていますが、財団がSingularityNETのハイレベルな監督を行うという点で異なります。私たちの意図は、時間とともにネットワークが真に分散化された自律的な組織へと発展していくことです。このような組織は、通常の企業とは異なり、何よりもその開放性が特徴です。
SingularityNETのスマートコントラクトには、ネットワーク上のAgentからAIサービスを受けたい外部の非AI Agentが使用するコントラクトも含まれています。誰でもノード(AIエージェント)を作成し、オンライン(サーバー、ホームコンピューター、ロボット、組み込みデバイス上で動作)にして、ネットワークに参加させ、他のノードと相互作用しながらAIタスクを要求・実行し、経済取引に従事させることができるようにすることができます。
図3.AIエージェント間の「交流の輪」の例
SingularityNET上のサービスは、AGIトークンを使ってアクセスすることができます。トークン保有者は、トークンを使ってマーケットプレイスでサービスを購入することができます。将来的には、トークンはネットワークの民主的ガバナンスシステムにお
ける議決権を付与することも可能です。
ネットワーク運用の初期段階では、ネットワークの中核となるパラメータは、非営利の財団によって管理され、監督委員会によって監視され、助言されます。財団はネットワークを運営し、悪用や不正を防ぐための監視を行います。
敵対的な振る舞いをする一方で、エージェント間インタラクションのシステム設計上のプライバシーを尊重します。
しかし、初期段階においても、SingularityNET上の活動は自己組織化されます。例えば、Agentは自由に新しいAI Agentを作り、ネットワークに挿入し、お互いに自由に、許可なく取引することができます。
図4.SingularityNETは、インテリジェントなシステムを育成し、そのポジティブなインパクトを最大化することを目的としている
SingularityNETは、ますますインテリジェントなシステムを育成すると同時に、これらのシステムのポジティブなインパクトを最大化することを目的としています。経済ロジックは、すべての人とすべての生命にとって最大の利益を追求する知的な世界経済を生み出すように設計されています。強力なAIエージェント、人間の意思決定、利益を最大化するゲームルールの組み合わせにより、SingularityNETはグローバルなスーパーマインドの開発を加速させ、人類がより高度で知的、有益、かつ結びついた存在へと進化することを支援します
つまり、SingularityNETは、人間と機械の知能を触媒として、倫理的に有益な自己組織化知能の新しい形態に向かうように設計された革新的な経済メカニズムです。この人工知能エージェントのグローバルネットワークは、誰にでも価値あるAIサービスを提供し、その過程でより高い目標に向かって自己組織化する。シンギュラリティNETが大きな成功を収めれば、人類が技術的特異点(シンギュラリティ)へ移行する際に大きな役割を果たすことは間違いないでしょう。
SingularityNETの成長は、実用的な狭義のAIだけでなく、有益な人工一般知能の一般的な理論と実践、倫理的に知的な経済の構造の設計と分析、そして “利益 “と “より大きな善 “を概念化し推定する手段を継続的に洗練させることで、進歩を促すでしょう。
1.5 SingularityNET 財団
オランダで法人化された非営利団体SingularityNET Foundationは、SingularityNETのネットワークとマーケットプレイスの構築、監督、成長の加速を担っています。
ネットワーク運用の初期段階では、ほとんどの主要なガバナンスの決定はトークン保有者によって民主的に行われ、財団はハイレベルなスチュワードシップと実用的な日々の管理を提供します。ネットワークが進化するにつれて、完全に自己規制された分散型自律組織へと移行する可能性があり、ネットワークの技術仕様とガバナンス手法は、これをサポートするように設計されています。
SingularityNET財団は、2017年末から2018年初めにかけて、以下の主要なグループによって結成されました。
● オープンソースの人工知能プラットフォーム「OpenCog」を運営するOpenCog Foundation
● 世界で最もリアルな人型ロボットを開発したHanson Robotics社
● Vulpem社:ブロックチェーンソフトウェアエンジニアリングコンサルタント会社で、設計に成功した多くのプライベートおよびパブリックブロックチェーン、暗号通貨、分散型アプリケーションのバックエンド作業を担当している。
● 2001年から企業や政府機関にカスタムAIソリューションを提供している人工知能ソフトウェアコンサルタント会社Novamente LLC社
高度な初期AIエージェント、活発なAIエージェント開発者のコミュニティ、そして様々なレベルの顧客からなる豊かなエコシステムをうまく組み合わせて作ることは、大変な仕事です。幸いなことに、設立チームは、SingularityNETのグローバルなブレインネットワークの基礎を築くために、豊富な経験やオープンソースのコードをプロジェクトに持ち込みました。しかし、このビジョンを実現するためには、ネットワーク上にソフトウェアを配置し、ガバナンスを民主化するために、設立チームによって生み出された草の根コミュニティの積極的な参加が必要です。
SingularityNET プラットフォーム
SingularityNETのビジョンを実現するには、AIエージェントがネットワークに統合するために必要なプロトコルやツールを提供する、設計が良く、効率的で柔軟な基礎ソフトウェアプラットフォームが必要です。SingularityNETのコンセプトを完全に具現化するプラットフォームの構築は中期的な取り組みとなりますが、2017年8月の開発開始以来、大きな進展がありました。
ここでは、2019年2月にリリースされたプラットフォームのベータ版のソフトウェアアーキテクチャを適度に深く説明し、その後、ベータ版後に追加される機能や改善点について、より高いレベルの見解を述べます。
2.1 SingularityNETベータ版 プラットフォームの概要
SingularityNETのプラットフォームには、AIサービスの分散型ネットワークを繁栄させるために連携する重要なコンポーネントが多数含まれています。コアコンポーネントには、機能的でスケーラブル、かつ拡張可能なシステムを実現するための多くのアーキテクチャコンポーネントが含まれています。私たちは、ブロックチェーンの相互作用、AIサービスの統合、抽象化を管理するいくつかの重要な決定と、オープンで規制や法的要件に準拠したAIマーケットプレイスを構築するという目標に導かれ、慎重なプロセスを経てこのアーキテクチャにたどり着いたのです。
まず、現在のブロックチェーンであるイーサリアムへの依存を最小限にすることを意識的に選択しました。この決断の動機となったのは、概念的な問題と現実的な問題の両方です。概念的には、我々はブロックチェーンにとらわれないことを望み、評判に基づいて独自のコンセンサスアルゴリズムを構築することを検討します。イーサリアムのブロックチェーン相互作用の速度、信頼性、およびコストから、その上に構築される拡張可能なシステムは、ガスコストとブロックマイニング時間による遅延を最小限に抑えなければならないことが決定されています。これらの決定は、すべてのブロックチェーンインタラクションを抽象化するツール(デーモン、CLI、SDK)の使用と、支払いのためのマルチパーティーエスクロウ契約と原子単方向チャネルの使用に反映されています。
第二に、AIサービスの統合についてですが、AI開発者の視点から、ネットワークをできるだけ抽象化し、学習曲線を短縮し、ネットワーク経由でAIサービスを提供する
ことに伴うオーバーヘッドを最小にしたいと考えました。さらに、この抽象化を、スケーラビリティ、堅牢性、配布・管理機能を提供するのに役立つ柔軟な単一のツールで実現したいと考えました。これは、サービスやネットワークとの通信に使用されるサイドカー・プロキシであるデーモンによって実現されており、近い将来、サービスが他のサービスを非常に簡単に見つけて呼び出すことができるようになる予定です。
最後に、私たちのマーケットプレイスをオープン性を損なうことなく規制に準拠させるために、プラットフォームで利用可能なAIサービスの完全分散型レジストリを実装しました。AIマーケットプレイスは、そのレジストリ(スマートコントラクト)を、サービス所有者と提供されるサービスの性質を網羅するデューディリジェンスプロセスを経た、キュレーションされたサービスの中央ソースで補完しています。
下図は、主要な構成要素と補助的な構成要素およびその役割を示しています。
図5.プラットフォームの主要構成要素
ネットワーク上でAIサービスを提供したい開発者にとって、最も重要なコンポーネントはSingularityNETデーモンであり、他のすべてのコンポーネントとのやり取りを抽象化するアダプタとプロキシです。デーモンは、スマートコントラクトや支払いとのやり取り、クライアントのリクエストの検証、その他の便利なタスクを処理します。これにより、AI開発者はサーバー側のソフトウェアやサービスのAI関連の側面のみに集中することができます。デーモンはサイドカー・プロキシなので、各AIサービス・インスタンスの隣にデーモン・インスタンスが1つずつ配置されます。
プラットフォームで利用可能なAIサービスへのアクセスを購入したいエンドユーザーにとって、最も重要なコンポーネントはMarketplace DAppで、これを介して、大規模で増え続ける様々なAIタスクのためのキュレーションされたサービス(つまり、SingularityNET Foundationによって関連性があり高品質であると承認され、その所有者がユーザーおよびデータプライバシー契約を締結したサービス)を検索して閲覧することが可能です。Marketplace
DAppは、サービスに対する支払い(MetaMaskの統合による)やサービスの評価も処理します。
ネットワークのインテリジェンスをアプリケーションで利用したいアプリケーション開発者にとって、重要な要素となるのがSingularityNET SDKです。このSDKは、クライアント側のコードを自動的にコンパイルします
プラットフォームや特定のサービスとのインタラクションのために、サービスリクエストをわかりやすくコーディングできるようにし、支払いやブロックチェーンとのインタラクションをサポートします。
イーサリアムのブロックチェーンは、2つの重要なスマートコントラクトであるレジストリと
マルチパーティーエスクロー
レジストリは、AIサービスプロバイダがプラットフォームに登録する場所であり、ユーザーがサービスを発見できるようにするためのテキスト説明やタグ、価格情報、ユーザーがサービスを呼び出せるようにするためのgRPCモデルやエンドポイント位置などの情報を提供する必要があります。マルチパーティーエスクロー契約は、各ユーザー(エンドユーザーとアプリケーション)のエスクロー口座を通じた支払いを処理し、原子単方向チャンネルと相まって、より速く、より安く
の取引を行います。
これらは、プラットフォームの中核となるコンポーネントです。また、2つの重要なサポートコンポーネントも特筆に価します。
● AI開発者・オーナー向けのCLI(コマンドラインパッケージ)は、IDの登録と管理、サービスの公開、登録情報の更新、新しいエンドポイントのプラットフォームへの通知、支払いチャネルと残高の管理、サービスの呼び出しなど、サービス開発者とサービスオーナーの重要なタスクの数々にコマンドラインAPIを提供します。
● Request for AI Portal(RFAI)は、エンドユーザーやアプリケーション開発者がネットワークに追加してほしい特定のAIサービスをリクエストし、高品質のソリューションに対する報酬としてAGIトークンをステークできるDAppである。
2.2 SingularityNET DaemonとWrapping サービス
デーモンは、サービスがSingularityNETプラットフォームとインターフェースするために使用するアダプターです。ソフトウェア・アーキテクチャの用語では、デーモンはサイドカー・プロキシです。7 -コア・アプリケーション(この場合はAIサービス)の隣に展開されるプロセスで、ログや設定といったアーキテクチャ上の懸念や、スマート・コントラクトとのやり取りやイーサリアム・ブロックチェーンの使用決定といったプラットフォーム全体の側面を抽象化するものです。
デーモンの2つの重要な抽象化責任は、支払いとリクエストの変換である。支払いを承認するために、デーモンはマルチパーティーエスクロー契約と相互作用する。SingularityNETを通じてサービスを呼び出す前に、コンシューマーは以下の条件を満たしていなければなりません。
マルチパーティーエスクロー契約(下記支払いに関する項目を参照)に資金を提供し、サービス定義で指定された受取人との支払いチャネルを開設しました。各呼び出しで、デーモンは以下をチェックする。
サインは本物です。
支払いチャネルに十分な資金があること。
7https://docs.microsoft.com/en-us/azure/architecture/patterns/sidecar。
支払いチャネルの有効期限が指定された閾値を超えている場合(開発者が未収金を請求できるようにするため)。
これらのチェックに成功した後、リクエストはサービスにプロキシされる。デーモンはまた、異なるクライアントの支払い状態を追跡する。
図6.SingularityNETデーモン
デーモンはリクエストを検証した後、AIサービスが期待するフォーマットに変換する。デーモンはgRPC(8 )を公開するので、全てのリクエストはgRPCとプロトコルバッファ(9 )に基づいていますが、サービスが期待するいくつかの異なるフォーマットにリクエストを変換することができます。gRPC/Protobufに加えて、JSON-RPCとプロセスフォークベースのサービス(入力パラメータを標準入力として呼び出しごとに実行される実行ファイル)もサポートされています。この変換により、SingularityNET上のあらゆるサービスと通信するために、一貫した1つのプロトコルを使用することができます。また、デーモンとCLIは、通信にgRPCとProtobufを使用しています。
1つのAIサービスの複数のインスタンスをデプロイすることができます。各インスタンスは独自のサイドカーデーモンを持ち、すべてのデーモンはレジストリにエンドポイントとして登録される。複数のインスタンスが存在する場合、それらを1つまたは複数のインスタンスグループにまとめることができます(そうする典型的な理由は、同じデータセンターまたはクラウド領域にあるインスタンスをグループ化することです)。同じグループのデーモンは、etcdを通じて支払い状況情報を共有するために連携する。10
このデーモンは、デプロイメントおよび管理指向の機能をいくつか追加しています。
8https://grpc.io/。
9https://developers.google.com/protocol-buffers/。
10https://coreos.com/etcd/。
● SSL の終了。これは、サービス開発者が提供する証明書とキーファイル、またはLet’s Encryptが提供する自動証明書によって行うことができます。11
● ログローテーションとプラグイン可能なログフックを備えた、ファイルへのログ記録。現在、メールフックが提供されており、他のフックについては使いやすいAPIが利用可能です。
● メトリックス、モニタリング、アラートデーモンは、リクエストコールに関するメトリックスを収集し、サービスオーナーがリソース使用を最適化するために使用することができます。また、デーモンとサービスのイベントを監視し、電子メールやWebサービスを通じて設定可能なアラートを提供します。
● DoS攻撃を防ぐため、またサービスオーナーが自分のスピードと能力で拡張できるようにするためのレート制限。このデーモンは、トークンバケットアルゴリズムを使用しています。12
● ハートビートgRPCヘルスに準じたプル型ハートビートサービスを提供します。
をチェックするプロトコルです。13デーモンは、サービスのハートビートを確認するために
を設定しました。これは、モニタリングサービスやMarketplace DAppで使用されます。
2.3 SingularityNET レジストリ
SingularityNET Registryは、ERC-165に準拠した、Ethereum上の14 スマートコントラクトです。
組織、サービス、タイプレジストリを格納するブロックチェーン。AI開発者はRegistryを利用してサービスの詳細を発表し、消費者はRegistryを利用して必要なサービスを探します。ユーザーがMarketplace DAppでサービスを検索すると、DAppはRegistryからサービスの詳細を読み取ります。また、レジストリでは、サービスやタイプのリポジトリにタグ付けすることで、検索やフィルタリングを可能にします。
レジストリは、組織、サービス、タイプリポジトリ、タグの4つの主要なデータを格納します。これらすべてのデータの作成、削除、編集、読み込みをサポートし、データを取得するためのいくつかのビュー関数が含まれています。
組織の下にグループ化するサービスのための傘であり、レジストリのデータ階層の最上位にある。サービス開発者ができます(とする)組織を登録し、その下にすべてのサービスを配置します。組織の登録レコードは、名前、所有者のアドレス(IDの意味で)、メンバーのアドレスのコレクション、サービスのコレクション、およびタイプリポジトリのコレクションがあります。
ある組織の下に登録されたサービスやタイプリポジトリは、その組織が所有すると
言われます。組織のメンバーは、組織の所有者を変更することと組織を削除すること以外は、すべて行うことができます。
サービスは、1つのAIサービスを表します。そのレジストリエントリは、コンシューマがそのAIサービスを呼び出すために必要なすべての情報を含んでいます。エントリには、名前、タグ、およびIPFSハッシュが含まれます。名前は発見性のための識別子であり、タグは顧客がサービスを見つけるのを助ける。
11https://letsencrypt.org/。
12https://en.wikipedia.org/wiki/Token_bucket。
13https://github.com/grpc/grpc/blob/master/doc/health-checking.md。
14https://eips.ethereum.org/EIPS/eip-165。
はその名前を知ることなく、IPFSのハッシュはIPFS上のメタデータファイルへのリンクとなります。DAppやスマートコントラクトは、listServicesForTagビュー関数を使用してサービスを発見することができます。
すべてのサービスのメタデータは、パフォーマンスとガスコストの理由から、IPFSのオフチェーンに保存されます。このメタデータには
● バージョン番号、サービス名、説明などの基本情報。
● エンコーディング(protobufまたはJSON)、リクエスト形式(gRPC、JSON-RPCまたはprocess)など、サービスを呼び出すためのコードレベルの情報です。
● デーモンのエンドポイントのリストで、1つまたは複数のグループに集約されます。
● 価格情報
● サービスAPIモデルのIPFSハッシュです.
CLIは、このメタデータを操作するための便利なAPIとライブラリを提供する。
型リポジトリとは、サービス開発者がサービスのメタデータ(サービスモデルや使用するデータ型など)を登録するためのレジストリエントリです。このエントリには、名前、タグ、パス、URIが含まれます。名前とタグは発見しやすくするためのもので、パスは組織内部で管理するための任意の識別子、URIはクライアント(エンドユーザーか、SingularityNET SDKを通じて呼び出すアプリケーションか)がメタデータを見つけるためのものです。DAppsやスマートコントラクトは、listTypeRepositoriesForTagビュー関数を使用してAIサービスを発見することができます。URIはIPFSハッシュで、ホスティング自体はSingularityNET、サービス開発者、またはInfuraなどのIPFSピンニングサービスのいずれかが行うことができます。
タグは完全に任意ですが、発見しやすくするために推奨されます。レジストリ機能により、サービスやタイプレポジトリにタグを追加することができます。その後、タグはDApp上に表示され、検索可能になります。レジストリのコントラクトに組み込まれたリバースインデックスのおかげで、他のスマートコントラクトもレジストリを直接検索することができます。これは、後述する「APIのAPI」機能の基礎となるものです。
Registryは、プラットフォーム上でAIサービスを見つけ、対話するために必要なすべての情報を、情報を完全にリストアップするか、情報が長すぎる場合はIPFSハッシュをリストアップすることで提供します。Marketplace DAppはエンドユーザーにとって便利なインターフェースであり、誰でもRegistryの情報を使って同様のマーケットプレイスを構築することができます。
2.4 マルチパーティーエスクローと チャンネルによるスケーラブルな支払い
マルチパーティーエスクローのスマートコントラクト(以下、MPE)は、当社の原子単方向決済チャネルと相まって、クライアントとAIサービスオーナー間で必要なオンブロックチェーンのトランザクション数を最小限に抑え、プラットフォームにおけるスケーラブルな決済を可能にします。MPEコントラクトは、主に2つの機能を備えています。
● 入金・出金機能を備えたシンプルなウォレットです。
● また、クライアントとサービスプロバイダ間の原子的な一方向の支払いチャネルのセットでもある。
決済チャネル15 は、当事者間のオフチェーン取引を無く、
ブロックチェーンのブロック形成時間によって課される遅延と、取引の安全性を損なうことなく。決済チャネルにはいくつかの種類がある。ここでは、単純な単方向の決済チャネルを考えてみよう。
● 送信者であるアリスは、指定された有効期限でエスクロー契約を作成する。彼女はエスクロー契約に希望のトークン量(例えば23)を入金する。
● アリスが5つのAGIトークンをボブ(「受信者」)に送りたい場合を考える。AliceはBobに、エスクローチャネルを閉じてそこから5つのAGIトークンを引き出すための署名された認可を送信する。
● Bobは、承認が正しく署名されていること、金額が正しいこと、金額がエスクロー資金を超えていないことをチェックします。
● ボブはアリスからの署名された認可を提示することで、いつでもチャンネルを閉じることができます。この場合、ボブにはアリスが認可した5つのトークンが送られ、 エスクローの残りの18トークンはアリスに戻されます。
● アリスは有効期限後にチャンネルを閉じ、すべての資金を取り戻すことができます。
● アリスはいつでも契約の有効期限を延長したり、資金を追加したりすることができます。
上のモデルでは、Bobがチャンネルを閉じずに資金を引き出す方法はありません。さもなければ、彼はアリスの署名された認証をもう一度使って、さらに5つのAGIトークンを引き出すことができる。
そこで、このリプレイ攻撃を防ぎつつ、ボブがチャンネルを閉じることなく資金を引き出せる機能を追加しました。私たちは、ノンスというシンプルで教科書的な解決策を用いました。送信者が署名するメッセージにnonceを追加し、受信者がチャネルを請求するたびにこのnonceを変更します。
この改良により、MPE内の決済チャネルは、以下のような良好な特性を持つようになりました。
● 送信者と受信者の間のチャネルは、無期限に持続することができます。送信者は、有効期限を延長し、チャネルに資金を追加することができます。受信者は、いつでも彼に署名された金額を請求することができます。
● イーサリアムのネットワークが数時間以上の確認時間を要する過負荷状態でも、以下の理由により、快適に動作します。
○ 送り手も受け手もブロックチェーンからの確認は必要ない。アリスは資金を追加し続けることができ、ボブはブロックチェーンからの確認なしで、チャンネルに資金を請求し続けることができる。例えば、ボブは資金を請
求した後、チャネルのnonceが変更されたことをアリスに知らせ、アリスは新しいnonceでメッセージの送信を開始することができる。これが送信者と受信者の両方にとって安全であることを示すのは簡単です。条件はただ一つである。
15http://super3.org/introduction-to-micropayment-channels/。
受信者は、トランザクションがチャネルの有効期限内に採掘されることを確認する必要があります。
○ 請求(受信者側)と資金の拡張・追加(送信者側)の間に競争条件はない。当事者はいつでもこれらの機能を利用することができ、最終的な結果はこれらの取引が採掘された順序に依存しない。
ユーザがあるサービスを呼び出したい場合、チャネルを開き、資金を追加し、サービスがその機能を果たすのに十分な時間を確保できる有効期限を設定しなければなりません。各チャネルは、クライアントID(送信者)、サービスID(受信者)、デーモングループのIDの組み合わせで一意に決まる。これにより、同じグループのデーモンがetdcを介して支払い情報を共有し、チャネルの全体的な数を減らし、クライアント側の生活を簡素化することができます。クライアントは、Marketplace DAppを介してプラットフォームと対話するエンドユーザー、または直接またはSDKの生成コードを介して呼び出しを行うアプリケーションとすることができます。
2.5 マーケットプレイス DApp
SingularityNET Marketplace DAppは、SingularityNET上のAIサービスを発見し、利用するためのエントリーポイントです。DAppは
● は、オンチェーン・レジストリからデータを読み取り、オフチェーン・メタデータと組み合わせて、AIサービスの検索、フィルタリング、発見を可能にします。
● は、SingularityNETのキュレーションサービスを統合し、レジストリから表示されるのは、デューディリジェンスを受け、ユーザーのプライバシーとデータを保護する法的契約を締結した所有者のみが審査されたサービスのみとなります。
● は、AIサービスがユーザーとのインタラクション(サービス実行のための入力収集や結果表示)のためのカスタムUIコンポーネントを表示することを可能にします。
● は、マルチパーティーエスクローと統合し、ユーザーがサービス利用料を支払うことを可能にします。
● 消費者が利用したサービスを評価することができます。これは単純な評価コンポーネントで、最終的にはSingularityNETのレピュテーションシステム(現在開発中)に置き換わる予定です。
● は、消費者レベルでの利用指標を把握することができます。
2.5.1 サービス一覧
以下の図は、DAppがさまざまなフローの中で統合されるさまざまなコンポーネントを示しています。
図7.DAppが様々なフローの中で統合する様々なコンポーネント
● DAppは、キュレーションされたサービス、サービスタグ、投票に関するデータをマーケットプレイスサービスから取得します。このサービスには、どのサービスがキュレーションされているかという情報と、スマートコントラクトに保持されパフォーマンスのためにここにインデックスされたいくつかの情報のキャッシュの両方が含まれています。
● 上記のデータとレジストリやIPFSから読み取ったエージェントの詳細をマージしてリスト化する。
● また、ユーザーがエージェントにアップボート・ダウンボートする仕組みも提供します。
DAppにはウォレットインターフェイスがあり、ユーザーは以下のことができます。
● エスクロー契約の預け入れおよび引き出し。
● チャネル(ユーザーが選択した特定のAIサービスに行く)に資金を入金し
● は、すべてのオープンチャンネルとそれぞれの資金を表示します。
2.5.2 サービスの実行
サービスが決まったら、実行される。
図8.サービスの実行
DAppは、そのインターフェイスにサービスを表示します。DAppは、マルチパーティーエスクロー契約と支払いチャネルを開き、サービスの支払いに十分な資金があることを確認します。そして、デーモンを介してサービスを呼び出す。DAppは、サービスから返されたレスポンスを表示します。
現バージョンのDAppは、MetaMaskを使用してイーサリアムのブロックチェーンと統合するため、すべての取引はMetaMaskを介して行われることになります。
レジストリのスマートコントラクトをクエリするとコストがかかるため、DAppは現在、レジストリのインデックスと検索を中央のサーバーレスコンポーネントに依存しています。レジストリのデータは依然としてイーサリアム・ブロックチェーンに保存されているため、これは単なるパフォーマンスの最適化です。DAppの将来のバージョンでは、この中央集権的なコンポーネントは削除されますが、SingularityNETの中央集権的なキュレーションは維持され、キュレーションされたサービスのみが表示される予定です。
2.6 開発者支援ツール。CLIおよび SDK
2.6.1 サービスプロバイダー向けコマンドラインインターフェース
SingularityNETのコマンドラインインターフェース(CLI)は、プラットフォームのスマートコントラクトとのやり取り、導入されたサービスの管理、資金管理を行うための主要ツールです。このツールは以下を目的としています。近い将来、ウェブベースのダッシュボードとコントロールパネルで補完される予定です。
CLIは、以下のような方法でブロックチェーンとインターフェースするためのコマンドを提供します。
● アイデンティティの作成と管理
● SingularityNETレジストリに組織、メンバー、サービス、タイプ、タグを登録し、管理すること。
● MPEおよびペイメントチャネルを使用して顧客から資金を請求すること。
● AIサービスに関するメタデータとProtobuf仕様の読み書き(これらはIPFSに保存され、基本的なサービスパラメータはブロックチェーンコントラクトから取得できる)。
● ローカルテストネット、Kovan、Ropsten、Ethereumメインネットなど、さまざまなネットワークに接続することができます。
また、CLIはサービスの開発とデプロイメントをサポートします。サービスのメタデータ、Protobuf仕様、SingularityNET Foundationが提供するコードテンプレートを生成して、新しいサービスをセットアップすることができます。CLIは各サービスのデーモンと対話する。
セキュリティ面では、CLIは秘密鍵の保管についてEthereumが提供するものと同じガイドラインに従っています。ユーザーIDが作成され、クライアントに登録されると、CLIはその詳細をローカルマシンに安全に保存し、ブロックチェーンとやり取りする必要があるときだけそれを取得する。
2.6.1.1 CLIの仕組み
図9 CLIの仕組みCLIの仕組み CLIは4つの重要なコンポーネントを必要とし、それに接続します。
● ユーザーのID管理。ユーザーの登録、アイデンティティとセッションの管理、ブロックチェーンと取引するためのアカウントのロック/アンロックに関与します。このコンポーネントは、CLIが実行されるマシンにローカルに存在する。
● デーモンです。Sidecarのプロキシ。AIサービスをホストするサーバーと通信する。
● レジストリ契約。組織、メンバー、サービス、タイプ、タグを扱います。
● MPE契約。資金の送受信や、決済チャネルに関連するその他の機能の管理(チャネルの閉鎖や有効期限の延長など)。
2.6.1.2 サービス登録と展開のワークフロー
あるAI開発者が、画像を分類する新しいAIを学習させ、それをSingularityNETでサービスとして立ち上げたいと考えたとします。このような流れになるでしょう。
IDを作成し、接続するネットワークを選択します。CLIを使用して、基本的なサービステンプレート(メタデータ、Protobufスペックなど)を生成します。必要なデーモンエンドポイント群を設定した上で、サービスを展開する。前の手順で作成したアイデンティティとネットワークを使用して、必要なメンバー、サービス、タイプリポジトリー、タグとともに組織を登録します。サービスがキュレーションされると、Marketplace DAppに表示されるようになります。それ以前でもレジストリを経由して見つけることができます。チャネルは、顧客が利用するサービスごとに作成されます。各チャンネルには、消費者が使用した資金が含まれています。CLIは、消費者のエスクロー資金からこれらのトークンを要求するために使用することができます。
2.6.2 サービス・コンシューマー向けソフトウェア開発キット
SingularityNET Software Development Kit(SDK)は、SingularityNETサービスをシームレスに呼び出し、SingularityNETプラットフォーム全体と対話するためのクライアントサイドライブラリを生成するものです。
少数のサービスの起動にはDAppやCLIが適していますが、SingularityNET上のサービスを大量かつ頻繁に本番利用するには、SDKを介して生成される専用のクライアントライブラリがより簡単で高速になります。
生成されるクライアントライブラリは、資金を供給されたウォレットのみを必要とするはずです。従来のSaaSプラットフォームのクライアントライブラリと同様に、ユーザーに代わってマルチパーティーエスクロウ契約でチャネルを開き、資金を供給し、サービスに対して整形式のリクエストを生成し、そのレスポンスを正しく解析することができるようになるのです。
SDKの初期バージョンは、現在機械学習やAIで最も人気のある言語であり、グルーコードの共通言語であるPythonをサポートしています。近い将来、Go、Javascript、Javaなど、他の一般的な言語によるバージョンも提供する予定です。
サポートされるプログラミング言語のリストは、いつでも拡張可能です。クライアントライブラリは gRPC フレームワークを利用しているため、gRPC “protoc” コンパイラがターゲットとするプログラミング言語のサポートは、最初のステップとしては簡単です。最終的には、他の言語をサポートすることも可能です。そのためには、SingularityNET Foundationまたはオープンソースコミュニティによって書かれたgRPC protocコンパイラのプラグインが必要となります。
gRPCを使ってサービスを呼び出すだけでなく、クライアントライブラリはEthereumやIPFS、SingularityNETの他のコンポーネントと対話できる必要があります。これは、言語ごとに個別のコードを作成するか、汎用のライブラリを(例えばCやC++で)ラッピングすることで実現できます。まだサポートされていない言語や操作については、開発者がSingularityNETを自分のプラットフォームに統合するためのドキュメントが提供される予定です。
コンパイル言語のクライアントライブラリは、ライブラリ内の各サービスの呼び出しを生成し、Ethereum、IPFS、デーモン、MPEコントラクト、ステートチャンネルとのやり取りを処理する追加のヘルパー関数を含んでいます。例えば、クライアントライブラリは、コンパイル時に特定のサービスで使用されるエンコーディングをデーモンに問い合わせ、リクエストを適切にマーシャルし、レスポンスをアンマーシャルするメソッドコールを生成する。クライアントライブラリはまた、チャネルIDのリストを保存し、そのような情報を財団またはトランザクションのパートナー(失敗するか、敵対的な方法で行動する可能性がある)から提供されたものだけに頼る必要がないようにするだろう。開発者は、これらのライブラリをアプリケーションコードに統合することになる。
JavaScriptやPythonのようなインタプリタ型言語では、2つの異なるオプションをサポートすることができます。両方のライブラリを特定のサービス用にコンパイル時に生成するか、より汎用的なライブラリを使用します。サービスのprotobuf仕様をダウンロード(またはローカルストレージからロード)し、そのサービス用のクライアントライブラリを実行時にコンパイルし(またはキャッシュされたコンパイル済みのクライアントを利用)、動的にサービスコールを生成します。後者の設計は、DApp、CLI、およびSDKのベータ版で使用されています。
現時点では、SDKの主な機能は、クライアントライブラリの生成とサービスの呼び出しを行うことです。将来的には、現在CLIで処理されている他のインタラクションを取り込むために拡張される予定です。例えば、ユーザーはさまざまなプログラミング言語で書かれたSDKを使って、レジストリのサービスをリストアップしたり、サービスのメタデータを変更したり、ユーザーがコントロールするさまざまなサービスのデーモンからデータ、ログ、メトリクスを収集・集計したりできるようになるはずです。これによって、AIサービスが新しいサービスを自動的に生成して登録できるようになり、人工知能がエージェントを展開できるようになる。
2.7 今後 改善予定
前項では、ベータ版リリースのマイルストーンである2019年2月時点のSingularityNETプラットフォームの全コンポーネントについて説明しました。本節では、今後のリリースでプラットフォームにもたらされる主なコンセプトの革新について説明します。
2.7.1 複雑なサービスの相互作用サービスオントロジーとAPI of API
SingularityNETでの基本的な取引では、ユーザーは単一のサービス・プロバイダーにトークンを渡し、プロバイダーは要求されたAIタスクを実行する。しかし、多くのタスクでは、複数のAIサービス・プロバイダーによる、より複雑な動作の組み合わせが必要になります。例えば、人型ロボットの制御には、自然言語処理、運動制御、音声合成など、複数のAIサービスが特定のアーキテクチャに従って連携する必要がある。
もっと簡単な例として、アリスがSingularityNETに、動画が埋め込まれたフランス語のウェブサイトを要約するよう依頼したとしよう。彼女のリクエストは文書要約サービスに送られるが、おそらくそのサービスは英語のテキスト要約に特化している。他のサービスに頼らなければ、アリスのリクエストは叶えられない。しかし、AIサービスのネットワークに依存することで、以下のような取り決めを作ることができる。ウェブサイト上のテキストは、ドキュメント翻訳サービスに送られ、英語版が返されます。また埋め込まれた動画は動画要約サービスに送られ、動画の中の重要な事実や出来事のテキスト要約が返されます。それは、フランス語の文章を理解したり、動画を処理したりすることはできないが、これらの結果をまとめて、ウェブサイトの要約に役立つ情報を提供するオリジナルの文書要約サービスである。
このようなサービス間の相互作用により、文書要約者は顧客に対してより高い価値を提供し、より多くの収入を得ることができるのである。さらに、他の2つのサービスに対する需要も拡大する。その結果、市場はより活性化する。相互作用はますます複雑化する可能性がある。ビデオ要約者は、顔認識、物体認識、音声検出、音声テキスト化などをアウトソーシングすることができる。ドキュメントサマライザーは、エンティティ認識を他のサービスにアウトソースすることもできる。それらのいずれもが、ストレージやGPUアクセスのために明示的にハードウェアサービスを雇うことができる。
この複雑でダイナミックな相互作用から、多数のネットワーク参加者が集合知を駆使して複雑なAIサービスを実行し、SingularityNET全体のAIマインドが、その部分の総和を超えるレベルの知性を持つようになるのです。(注目すべきは、現代の神経科学の最良の理解として、人間の脳では、一般的な知性は、それぞれが独自のアーキテクチャと一連の機能を持ち、慎重にパターン化された方法で特定の他のサブネットワークに接続された、300から400の異なるサブネットワークが一緒に働くことによって出現するということです)。さらに、世界中のAI開発者がネットワークに新しいノードを追加し、SingularityNETの経済に貢献し、そこから利益を得ることで、この出現したAIマインドは継続的に強化されるでしょう。
このプラットフォームは、3つのレイヤーリソースを通じて、これらの複雑なインタラクションを可能にします。
一番下にあるレジストリのタイプリポジトリでは、サービスが標準的な方法で入力と出力を記述することができます。サービス広告では、以下のようなことが言えます。
a. この与えられた型(”text”)の出力を提供します。
b. この与えられた型と値の出力を提供する(例えば、”Language “は “English”)。
50
c. このようなタイプの入力が必要です。
d. 私はこの与えられた型と値の入力を必要とする(例えば、”Language “が “English “であれば文書を要約できる)。
型リポジトリの上に構築され、具体的な型データやメタデータを参照する、APIのコレクションを持つことになります。これにより、「顔認識」、「文書要約」、「ゲノムデータセット注釈」などのAIタスクの標準仕様が実現されます。これらのAPIは、各サービスが既に提供している標準的なgRPCの仕様を、より活気あるセマンティックなものにしたものです。APIは公開されているため、どの開発者でも同じサービスを提供する複数のAPIを実装することができます。
トップレベルでは、APIを理解し閲覧できるようにするため、AIサービスのオントロジーを作成します。このオントロジーは、例えばAIの分野やアプリケーション・ドメインなどをカバーする、いくつかの異なるルートを持つ有向無サイクル・グラフになります。つまり、「顔認識」はオントロジーのどこかにあり、「画像処理」「ディープニューラルネットワーク」などのノードの子ノードになります。
この3つのレベルにより、開発者は自分のデータを入力として受け入れ、目的の機能を実行するサービスを見つけることができる。上の例のドキュメントサマライザーAI開発者は、ジョブを完了するために必要な補助サービスを特定するためにこの構造を必要としています。
各レベルの仕様が十分に精密であれば、他のAIをつなぐAI、つまりプログラムによるサービスファインディングの出現も可能である。これらはマッチメイキング・エージェントと呼ばれる。
評価者となるAIサービスを開発し、ネットワーク上で立ち上げることができます。彼らは、特定のサービスが行う作業の品質を評価し、格付けすることに特化する。これにより、ユーザーは、特定のサービス(例えば、顔認識)を提供し、特定のAPIに対応し、独立したAI評価者により一定の基準を満たすサービスを検索することができるようになります。これらの自動化された評価は、消費者にとって有用であり、マッチングエージェントにとって非常に価値があり、次のセクションで説明するレピュテーションシステムへの重要な入力となる。
独立した評価者と公開された標準APIにより、マーケットプレイスへの新規参入者は簡単に顧客を見つけることができます。新規参入者は、一般的なAPIをサポートすることで、既存のプロバイダをプラグアンドプレイで置き換えることができ、独立した評価機関を利用して、サービスの品質をマーケットプレイスに示すことができます。
特に大企業のお客様には、市場にある新しいエキサイティングなサービスをスキャンし、特定の問題(例えば、金融データセットのパターンを見つけるなど)でそれらをテストし、お客様がA/Bテストやマルチアームドバンディット選択に基づいてサービスを選択できるように、専門エージェントを開発することが可能です。
2.8 レピュテーション システム
SingularityNETのサービスが増えれば増えるほど、同じ機能を持つAIサービスが多数存在することになります。AIサービスの利用者(人間、本人AIを問わず)は、以下のような問題に直面することになります。
それを選択することになります。SingularityNETの評価システムは、各サービスが過去の仕事に基づいて得た評価を数値化することで、この選択をナビゲートしてくれます。
これは、ネットワークにおける日常的な取引に関する選択を行う上で重要であり、ネットワークのガバナンスや資源配分においても中核的な役割を担っています。
評価システムの設計は複雑で、SingularityNETの評価システムもネットワークとともに進化する必要があります。現在、消費者による明示的な評価、金融取引の痕跡、詐欺や悪意のある行為を検出するための機械学習を組み合わせた初期設計を実験しています。
最も基本的なレベルでは、トークンと(あるいは他のサービスと)サービスを交換するたびに、関係者全員が互いを[0, 1]の尺度で評価するよう求められます。この単純なバージョンでは、AIサービスの評価は、過去の評価決定の分布となります。評価は、何回評価されたかを示すカウントを伴う平均値に単純化することができる。平均値には時間的な減衰が含まれるため、より新しい評価がより遠い過去の評価よりも重く評価されます。
消費者とプロバイダーは、互いに評価し合うことを要求されていない。顧客が支払いを保留し、エスクローの仲裁を引き起こした場合は、サービス・プロバイダに不満があると仮定して安全であり、顧客が戻ってきた場合は、満足していると仮定することができるなど、彼らの行動から推測できるデフォルトもあります。消費者とプロバイダがどのようにチャネルを管理するかは、信頼(実質的なコミットメント、長寿命のチャネル)または不満(チャネルが期限切れ後に更新されない)を示すことができます。
格付けは多次元的に行うことができます。この多次元評価システムは、SingularityNETの経済モデルおよびガバナンスモデルの重要な構成要素です。評価の次元には、一般的なサービスパフォーマンス、適時性、正確性、金銭に対する価値などを含めることができます。その他の側面は、ネットワーク参加者がその良い影響力を証明するためにとった手段を反映しています。以下はその例です。
● レーティングマーク
● AIサービスの有益なタスクに限定した評価から得られる「有益性評価」コンポーネント(これは、将来的に有益なタスクにアクセスするための鍵となる)。
● KYCサービスによって提供される信頼できる企業による所有権の証明、またはデータプライバシー規制を守ることを約束する法的契約など、外部のアクターによる検証。
● オープンソースソフトウェアの場合、宣伝しているコードがリポジトリ内の特定のリリースと一致することを確認するチェックサムによる検証。
評価システムには複数の次元と概念的側面が必要ですが、例えばエージェントの基本的な整合性と信頼性を評価するために、ある目的のために単一の数値の評価を持つことは価値があります。この要件を満たすために、SingularityNET評価システムは、0から5の間の実数である各エージェントの「基本評価」レーティングを含んでいます。いくつかの目的では、数2が「基本レピュテーションのしきい値」として使用されます。例えば、ガバナンスへの完全な参加は、2以上のベースレピュテーションを持つAgentにのみアクセス可能です。
評価システムの不正や攻撃に対する防御は微妙な問題で、悪意のある参加者を検出するために取引と評価のパターンを分析する専用のさまざまな機械学習モデルが必要になると思われます。これは、SingularityNETで活発に研究されている分野です。
2.8.1 レピュテーションシステムコンセプト
中央集権的なガバナンスを持たない分散型コンピュータシステムが出現して以来、参加者の評判を検証することが問題になっている。この問題は、多くの側面から研究されてきた。ネットワーク上のすべてのノードが他のすべてのノードと通信できるピアツーピア・マーケットプレイスでは、評判を決定する信頼性の高い方法が重要です。
このような解決策の標準的な理論的枠組みは、ビザンチン将軍問題に由来する。この問題は、可変数の参加者(信頼度は可変)が、コミュニティ全体に知られるように公開台帳に記録されるべき決定に達するために独立に投票することを特徴とする。
攻撃者が多くの悪意あるノードを立ち上げ、それらが一緒に行動して攻撃者に有利な合意を引き継ぐ危険性があります。これに対する防御を設計する必要がある。
現在のブロックチェーン技術の実装では、コンセンサスを得るために様々な形式の重み付け投票が使われています。例えば、ステークされたトークンによる重み付けもあれば、計算能力による重み付けもある。各コンセンサスアルゴリズムは、ノードの信頼性を推定するための特定のヒューリスティックを提供する。
2.8.2 レピュテーションシステムオプション
複数の入力を用いて評価を計算することができる。
● まず、消費者が製品やサービスの提供を受けたサプライヤーを評価するために用いる明示的な格付けがある。
● 第二に、ステークホルダーが支援するサプライヤーに対して、明示的な利害関係を提起することができます。
● 第三に、消費者からサプライヤーへの支払いに基づく間接的な格付け情報が存在する可能性がある。例えば、複数回の支払いは、消費者がサプライヤーを高く評価していることを示唆する場合がある(リピーターは満足度の高い顧客である)。
● 最後に、既知のベンダーの評判に関する情報は、オンラインのニュースソースやソーシャルメディアから抽出することができ、その評判を説明する必要があります。
最も単純なケースでは、評判システムのインスタンスが1つだけ存在する可能性があります。しかし、信頼度の低い分散システムでは、一緒に行動する評判サービスの複数のインスタンスは、より正確に評判を計算することができるかもしれません。これらのインスタンスは、レピュテーションに関するコンセンサスに達するために、互いにクロスチェックします。次に、複数のレピュテーションサービスは、ロードバランシングまたはドメイン固有のレピュテーションを提供するために、コミュニティの異なるセグメントのレピュテーションを計算し、集約サービスによってマージされる可能性があります。複数のタイプの分散された計算は、コミュニティの異なるセグメントは、評判サービスの異なるグループによって計算された評判を持っているように、同じネットワークで行われることがあります。
2.8.3 レピュテーション「Liquid Rank」アルゴリズム
Liquid Rankは、このブログ記事で紹介されている評判を計算するためのアルゴリズムです。このアルゴリズムは、複数のパラメータと入力を考慮することができます。主に、異なる入力の評価について、評価の評価値、それぞれのインタラクションの財務的価値、評価を供給する主体の評価ランク、評価が提供された時間、などを考慮します。
リキッドランクは、Google の PageRank アルゴリズムを拡張したものと考えることができ、金銭的価値を考慮するため、よりマーケットプレイスに適しています。より高価で、より新しい支払いは、サプライヤーの評判により多くの影響を与えます。PageRankと同様に、評価者の評判が高ければ高いほど、評価者の評価も高くなります。
このアルゴリズムは、リアルタイムで実装され、すべてのトランザクションがコミュニティ内の評判ランクを変更するように、または段階的に実装され、コミュニティのメンバーの評判は、毎時、毎日、毎週、または毎月計算され、更新されます。実用的な観点から、段階的なバージョンは最も費用対効果が高いと思われ、特定の期間はシステムパラメータとして設定することができます。
極端に簡略化すると、時刻tにおけるエージェントiの評価は、以下のように、前時刻(Ri t-1)の自身の評価に、t-1からtまでの間に他のエージェントjから受けたすべての新しい評価を加え、これらの評価者の前時刻の評価を乗じたものである。
Ri t = Ri t-1 + Σj ( Rj-1 t* Vi j t )
評判は、その専門知識の分野で高い評判を持つ供給者が他のドメインではるかに低い評判を持つかもしれないように、選択されたドメインのために特別に計算されるかもしれません。同じドメイン内では、異なる特性(適時性、コスト、正確性など)に対して異なる評判のスコアが計算されることがあります。これらの細かい評判は、評判システムの最初のバージョンに含まれていない可能性があります。
2.8.4 レピュテーションポリス
レピュテーションポリスの目標は、レーティングやステーキング活動で悪意のあるパターンを検出するために、定期的またはアドホックな検査を実行することです。その過程で、少なくとも2つの解決すべき問題があります。
● 自然な協力と偽りの協力悪意のある攻撃者は、ネットワーク上の多くのエージェントをコントロールし、互いに高い評価を与え、人為的に評判を高めるために金銭を送金することができる。このため、悪意を持って作られたエージェントのリングと自然なリングを区別する必要がある。例えば、エージェントAがエージェントBに画像認識サービスを提供し、エージェントBがエージェントAに文章要約サービスを提供し、お互いに支払いを行った場合、見分ける方法はありません。
AとBの間で行われた評価を、ループを形成しているというだけで割り引くことはできません。そうすると、コミュニティのメンバーが相互にサービスを提供することを躊躇してしまうからです。これを解決する唯一の方法は、この種のサークルやリングの存在にフラグを立て、関係するエージェントを検査したり、ソースコードを監査したり、「覆面調査」を行い、これらのエージェントにサービスを注文して、有効なサービスを実行しているかどうかをチェックすることです。
● 時間的スパンでの協力。アリスは1月にボブの評判を上げ、そして7月にボブはアリスの評判を上げるかもしれません。これは有機的に起こるかもしれませんし、評判システムを操作するために協力しているかもしれません。我々のデザインに組み込まれたパターン認識を使って、協力が偽物か自然かを見極めることが可能なはずです。
疑わしいエージェントが発見されると、手動によるエージェントシステムおよびコードの検査、自動または手動による覆面調査、その他の実施活動により、不正を確認することができます。疑わしいエージェントが不正と確認された場合、手動、半自動、または自動の方法で予防措置を実施することができます。そのエージェントはSingularityNETから排除されるか、あるいはその活動がコミュニティに公に報告され、賭け金評判の提供者がその賭け金を回収できるようにするか、あるいは高い評判のエージェントを指名して、罪を犯したエージェントに対して「修正ダウンボート」のためにその賭け金を使わせることができます。
2.9 AI Infrastructure as a サービス
SingularityNETは、AIのイノベーションと実世界での応用の間の障壁を取り除くために構築されています。私たちは、新しいアルゴリズム、技術、モデルを考え出した研究者や開発者が、SingularityNETを、その技術を展開し、顧客を見つけ、それにふさわしい金銭的、評判的報酬を得るための最良の方法として見てほしいと考えています。
このミッションでは、AI開発者が最も得意とすることに集中できるように、またAI利用者が望むサービスが高い稼働率、堅牢性、性能を持ち、安全でスケーラブルな環境で展開・管理されると確信できるように、当社がAIサービスの展開と管理の側面を取り扱うことが求められています。私たちは、アプリストアがユーザーや開発者のためにモバイルアプリ経済を簡素化したのと同様に、AIインフラを手数料または収益のシェアでサービスとして提供します。
私たちの「AI-infrastructure-as-a-service」ツールは、AWSやAzureなどのプラットフォームによる同様のツールの役割を果たしますが、ネットワークAIのニーズに合わせて、以下の設計目標を掲げています。
● 機械学習モデルの学習と展開に必要な計算量を最適化する。これは、ディープニューラルネットワークやGPUの使用を超えて、グラフ処理、マルチエージェントシステム、動的分散ナレッジストア、およびネットワーク型AGIの出現を可能にするために必要なその他の処理モデルを考慮したものである。
● 現在のクラウドプラットフォームでは課題となっているステートフルサービスのスケーラブルな処理をサポートしますが、会話型エージェント、タスク指向の拡張現実感、パーソナルアシスタントなど多くのタスクで必要とされます。
● パブリッククラウド、プライベートクラウド、ハイブリッドクラウド(パブリックとプライベートのミックス、エッジとクラウドのミックス)の安全なサポートを含む。
● コンピュートロケーションを動的に最適化することで、コンピュートとデータの近接性を最大化し、パフォーマンスの向上と帯域幅のコスト削減を実現します。
私たちは、KubernetesやOpenStackなどの重要なオープンソース技術を活用し、既存のクラウドプラットフォームの上(組み込みツールを最適に利用する場合)とベアメタルデータセンターの両方で、当社のインフラストラクチャー・アズ・ア・サービス(IaaS)ソリューションの展開をサポートする予定です。AIモデルや長時間稼働するAI推論・推察タスクを訓練するために、暗号通貨マイニングハードウェアを使用することも重要な検討事項のひとつです。
2.10 ロボットや組込み機器への展開
SingularityNETのサービスの多くは、強力なコンピューティングリソースを必要とするため、クラウドでホスティングされることになります。しかし、SingularityNETのネットワーク自体は重量級ではないので、ネットワーク上のサービスをロボットやIoTデバイスなどの低電力デバイスに埋め込むことは十分に可能です。これらの部品は、SDKやデーモン機能を提供する組み込みコンポーネントを実行し、ネットワーク上の他のサービスを呼び出すと同時に、自らもサービスを提供します。例えば、センサーはあまり計算を必要としないデータフィードを提供することができます。このように、エッジに組み込まれたネットワークノードとクラウドベースのコンピューティングパワーの組み合わせは、IoTとロボティクスに多くの可能性をもたらします(明らかなものもあれば、創造的で予想外のものもあります)。
また、ハンソン・ロボティクス社の人型ロボットや他のプロバイダーのロボットが、マイクロペイメントと引き換えにクラウドベースのSingularityNET AIサービスから認知サービスを取得したり、他のSingularityNETネットワーク参加者からデータと引き換えにマイクロペイメントを受け取ることが可能になる。また、インターネット接続が困難な場所でも、純粋にローカルなネットワーク上の相互作用に基づき、ロボット同士が小規模な経済取引を行うことも可能になります。
2.11 ブロックチェーン 不可知論
SingularityNETプラットフォームは現在、イーサリアム・ブロックチェーンに依存しています。採用を拡大し、スケーラビリティを向上させ、その他の目標を達成するために、他の既存のブロックチェーン技術をサポートすることが有用であるか、あるいは必要である可能性もあります。プラットフォームのアーキテクチャはこのような可能性を考慮して設計されており、レジストリやMPEコントラクトとのすべてのインタラクションを小さなコードコンポーネントに集中させることを試みています。
2019年を通して、それらのコンポーネントを可能な限り汎用性を持たせてライブラリ化することに取り組みます。他のどのブロックチェーンをいつサポートするかはまだ決定していませんが、コードをライブラリにカプセル化することで、プラットフォームが進化しても他のブロックチェーンをサポートする可能性が保たれ、必要な作業量も管理可能なものになります。
2.11.1 評判に基づくコンセンサス
私たちは、ステーク、ネットワークでの活動、特定の評価側面(特に利益評価)、特定の閾値以上の活動と評価レベルの経過時間の長さ、およびその他のいくつかの要素を組み合わせて、私たちがProof of Reputationと呼ぶステーク証明の合意アルゴリズムの進化版をテストする予定です。機械学習は、要因の組み合わせを最適化するために使用することができます。
私たちがProof of Reputationで意図していることと、NEMブロックチェーンの「Proof of Importance」フレームワークの間にはかなりの重複があります。16 、私たちのProof of ReputationはNEMのアイデアとおそらくそのアルゴリズムの一部を借りることになるでしょう。プルーフ・オブ・ワークのコンポーネントも望ましいかもしれませんが、私たちは暗号パズルにサイクルを費やすよりも、むしろ有益な機械学習の問題を解決したいと考えています。このような機械学習タスクの計算コストは、ほとんどの暗号パズルよりもはるかに大きいため、このアイデアは今後数年間で洗練される必要があります。改良と実験の末に、NEMのような側面と機械学習ベースのプルーフオブワークのコンポーネントを組み込んだProof of Reputationフレームワークを完成させる可能性が高いと思われます。
2.12 現行 のコンポーネントのインクリメンタルな改善
先ほど説明した新しいコンポーネントに加え、既存のコンポーネントについても、AI開発者や消費者にとってより使いやすく、柔軟なプラットフォームとなるような改善を予定しています。これらの改良は、2019年を通じて徐々にリリースされる予定で、以下のものが含まれます。
● AIサービス所有者向けのウェブダッシュボードとコントロールパネル。サービスのモニタリング、計測、ロギングなどの使用統計情報を提供し、サービスの登録と管理を可能にします。
● 柔軟な価格設定により、月ごと、年ごとの定額制サービス(オプションで使用量に上限を設定可能)や一括割引が可能
● AIサービスの非同期およびストリーミングリクエスト対応
● 注入可能なAIサービスのUIコンポーネントを備え、中央集権的なマーケットプレイス検索サービスを必要としない、リファクタリングされたマーケットプレイスDApp
● Java、Javascript(Node.js)、Go向けのSDK
● AIサービス間の呼び出しをより便利にする、デーモンが提供するフルサービス・メッシュの抽象化。
16https://nem.io/NEM_techRef.pdf。
民主主義 ガバナンス
SingularityNETは、AIエージェントのネットワークであるだけでなく、AIを利用し、創造し、評価し、その他AIと相互作用する人間のネットワークでもあります。分散型組織であるため、SingularityNETの継続的な健全性と成長は、ネットワーク参加者による民主的な意思決定に依存することになります。ネットワーク運営に関する意思決定や、新たに鋳造されたAGIトークンの割り当てには、民主的なプロセスが用いられます。
3.1 評判とステークに基づく 投票
投票はレピュテーションによってフィルタリングされます。基準レピュテーションが2以上のエージェントのみがカウントされます。さらに、適切なKYC手続きによって所有者が確認されたエージェントのみが投票することを許可されます(他のエージェントはサービスを提供または購入することによってネットワークに参加することができますが)。
初期のデフォルト計画では、ブロックチェーンベースの企業のためのKYCを専門とする外部企業との提携を通じて、標準的なKYC手法を使用する予定です。ネットワーク運用の4年目までには、これを分散型のKYC手法に置き換え、Agentは中央機関ではなく、他のAgentによって「KYC」されるようになる予定です。一つの可能なアプローチは、基本的にKYC機能を実行するために民主的に承認されたAgentからなる「検証フェデレーション」です。
コアネットワークの運用問題や将来の開発準備金の分配に関して、オーナー(代理人を所有する検証済み事業者)が持つ議決権の量は、以下の式で与えられます。
ステーク(O)は、そのすべてのエージェントにわたって所有者Oの総ステーク(すなわち、AGIトークンの保有総量)を表すとします。ステーク(A)は、特定のエージェントAのステークを表し、Rep(A)はエージェントAのベースレピュテーションを表すとします。
以下の定義を用いる。
ここでLは境界であり、x < Lのとき関数Ψは区分的に線形に振る舞い、x ≥ Lのとき関数Ψは対数に振る舞う(そしてcは単なる任意の正規化係数である)ようにする。
そして、次のように設定します。
この方式では、レピュテーションとステークを組み合わせることで、より評価の高いエンティティに多くの投票権を与える一方、良いレピュテーションを持ちながらほとんど取引を行わないソックパペット・エージェントが大量に関与する攻撃を防止することができます。
この投票式は、高次元では「貢献の証明」のようなものだと考えることができる。
● 式の第一項で対数関数を用いているのは、AGIトークンの多い所有者はより多くの投票権を得るが、トークン所有量がLを超えると、その投票権は線形ではなく、AGI所有量の大きさに応じて増加することを意味している。
● 式の第2項は、エージェントが有用な(評判の高い)ことを行っている所有者が、より多くの投票権を得ることを意味する。Ψ関数の使用は、所有者がAI機能を多くの小さなエージェントに分割することで報酬を得るというダイナミズムを回避することを意図しており、それぞれが小さな賭け金だが良い評判を得ている。Lサイズまでの賭け金では、そのサイズより小さいエージェントを分割しても報酬はない。L以上の賭け金では、そのサイズより小さいエージェントを分割することに何らかの報酬がある。これは、あるサイズより小さいビジネスと大きいビジネスを区別して扱う法律と似ている。Lというパラメータは、例えば、およそ100,000AGIトークンに等しくなるように初期設定することができます。
ネットワークにおける民主主義の仕組みは、流動的(または委譲的)民主主義に基づいている。つまり、あるエージェントAが意思決定に対して投票する資格を持つとき、エージェントAはその投票権を他のエージェントBに委譲することも選択できる。(例えば、あなたが他のエージェントに慈善事業のデューデリジェンスを任せている場合、どのプロジェクトが有益かという決定については投票権を委ねるが、それ以外の決定については委ねないようにすることができる)。ネットワークは、自動的に投票を委任するための標準的なスマートコントラクトを提供しますが、もちろんAgentはこの目的のために好きなツールを使用することができます。
ネットワークへの大きな変更は、小さな変更よりも多くの票を必要とします。大きな変更とは、例えば以下のようなものを指します。
● 異なる目的に割り当てられたトークンの割合の変化(例:キュレーションリワードとベネフィットトークン)。
● は、ベースレピュテーションの算出方法を変更しました。
● は、ネットワーク経済を支配する定量的なパラメータを変化させます。
● 最初に採掘されたトークンを超えるAGIトークンの生成に関するあらゆる決定、または
● 異なるブロックチェーンやコンセンサスアルゴリズムへの移行など、主要な設計変更を行う。
マイナーチェンジとは、エージェント間のやり取りで使用するAPIやオントロジーを変更するようなことを指します。
利益タスクに関する決定には、評判の良いAgentによる投票と利益投票を組み合わせて用いることを提案する。ネットワークはAgentの利益品質評価に比例して、利益票をAgentに与える。(特典タスクに関する「大きな変更」は、タスクを特典タスクとして認定するシステムの変更である)。
3.2 完全な 民主主義への移行
ネットワーク構築の初期段階においては、財団がガバナンスの決定の一部を行う。意思決定は、ネットワークの成熟に伴い、段階的に純粋な民主的ガバナンスに移行し、その具体的内容は以下の通りです。
● ネットワーク運用の1年目および2年目(最初のトークン発行イベントの後)には、大きな変更はネットワーク開始時に設置された財団の細則に従って財団が決定し、小さな変更はAGIトークン保有者の51%の多数決で決定することになっています。
● 3年目、4年目
○ SingularityNETの運営を大きく変更する場合:財団の同意+AGIトークン保有者の51%以上の議決権
○ SingularityNETの運営に関する軽微な変更:AGIトークンの投票数の51%以上
○ 給付業務に関わる重要な決定:財団の同意+AGIトークン投票数51%+給付投票数51
● 5年目以降
○ SingularityNETの運営を大きく変える:AGIトークンの投票数の65%超の賛成
○ SingularityNETの運営に関する軽微な変更:AGIトークンの投票数の51%以上
○ 福利厚生業務に関する重要な決定:AGIトークン投票の65%超と福利厚生投票の65%超を必要とします。
3.3 ベネフィットに関する意思決定 タスク
SingularityNETでは、ネットワーク資産の一定割合を “ベネフィットトークン “として指定することになっています。(正確なパーセンテージは、このセクションで説明する民主主義のメカニズムによって決定されます)。そして民主主義は、どのような仕事を「有益」と見なすかについて投票します。
病気の治療法を研究しています。ネットワーク上のエージェントは、有益な仕事をすることで、この指定された利益トークンを獲得することができます。
どのエージェントが行うどのタスクがベネフィットトークンを得る権利があるかを決定するために、特定の民主的メカニズムが使用されます。他の意思決定と同様、これは財団の管理から完全に民主的な管理へと移行する。
我々は、利益決定者の役割を紹介する。ネットワークによって認可されたエージェントで、特定のタスクがベネフィットトークンの受領者として必要な条件を満たしているかどうかを決定する。
を提案します。
● 各代理店には、特典の評価に応じて、毎月一定の数の「特典投票」が行われます。
● ベネフィットタスクは、カテゴリに割り当てられます。あるカテゴリーをベネフィットタスクとして検討するためには、その月に行われたベネフィット投票の2%によって推薦される必要があります。新しいタスクを提案し、投票を募り、簡単に投票できるウェブベースのツールを作ることもあります。
● 資格のある利益決定者があるタスクカテゴリを利益タスクの候補として推薦すると、コミュニティはそれを利益タスクとして承認すべきかどうか投票します。このときの投票権は、便益の評価に比例します。投票数の25%が賛成票であった場合、そのタスクの種類は便益タスクとなる。
● 給付タスクが承認されると、それを実行することができ、十分に高いレーティングと給付評価を有するAgentは、それを行うことで給付金を受け取ることができます。
この種の研究開発に貢献する分散型コミュニティのインセンティブを高めるため、当初(そしておそらく継続的に)利益理論の改善に関する研究は利益タスクとして評価されるでしょう。
ハイレベルなAIサービス
大規模で繁栄するSingularityNETには、複雑な方法で相互作用する様々なタイプのAIエージェントが含まれます。あるAIエージェントは非常に抽象的な数学的アルゴリズムに特化し、他のAIエージェントは具体的なエンドユーザー・サービスを提供し、バックエンドのアルゴリズムは他のAIエージェントにアウトソーシングすることになるでしょう。
財団は当初、独自のAgentをネットワークに蒔く予定です。この作業では、「コアAIアルゴリズムサービス」と「ハイレベルAIサービス」を区別しています。後者は、エンドユーザーに対する具体的な具体的機能です。グレーな部分もあるかもしれませんが、この区別は、一般的に “AIエージェント”について考える以上に、価値ある明確さを加えます。
このセクションでは、SingularityNET FoundationのAI開発チームが開発しているドメイン固有のハイレベルなAIサービスの一部をレビューします。次のセクションでは、SingularityNET財団のチームが進めているAIの研究開発を掘り下げ、その一部はすでにSingularityNETネットワーク上で試作されたAIエージェントとハイレベルAIサービス内で使用されるに至っています。その他は、2019年後半または2020年にSingularityNET上でローンチする予定の初期段階です。
4.1 概要
4.1.1 AIソリューションの必要性
最近のAIの進歩は、私たちの生活様式を劇的に変えるようなインテリジェントなアプリケーションの爆発的な普及を促進しています。以下の図10は、製品やサービスにAIを使用している膨大な数のエンタープライズ企業を示しています。製造業から人事部まで、あらゆる垂直・機能領域でアプリケーションを見つけることができます。例えば、製造業では、ディープニューラルネットワークを使用して、既存の技術のスピードと精度をはるかに上回る製造上の欠陥を迅速に特定しており、人事担当者は、AIを使用して、何千もの履歴書をふるいにかけて、候補者の短いリストを効率的に構築しています。
McKinsey Global Instituteは、2018年のAI市場の評価において、ディープニューラルネットワークの影響だけで3.4兆ドルから5.7兆ドルの組織に対する価値の増分があると推定しています。
これらのアプリケーションはすべて、AIアルゴリズムによって駆動され、顧客ソリューションを提供するAIサービスとしてパッケージ化されています。SingularityNETは、このようなAIサービスをネットワーク化し、誰もが最先端のAI技術を利用できるようにするもので、誰でも貢献することができます。
図 10.AIをサービスとして提供する企業、またはAIを組み込んでいる企業
プロダクト/サービス提供
4.1.2 AIサービスとは何か?
最も抽象的なレベルでは、SingularityNET上のAIサービスは、入力と出力のセットを持つ関数であると考えることができます。このサービスは、特殊な単位作業を行う低レベルのサービスであったり、全体的な機能のコンポーネントを完成させるために一連の低レベルのサービスを呼び出す高位のサービスであったりする。
例えば、下の図11で、Aは上位のAIサービスである。これは3つの低レベルのサービスを呼び出す。A.1、A.2、およびA.3です。
EはSingularityNET上の別の高レベルのAIサービスである。Aのサービスを呼び出すのは、他にソフトウェアアプリケーションであるApp 1と、別のブロックチェーン上のスマートコントラクトであるS1である。
図11 SingularityNET上のAIサービスSingularityNET上のAIサービスは、他のSingularityNETのサービスから、他のブロックチェーン上のスマートコントラクトから、アプリケーションから、あるいは直接、様々な方法で呼び出すことができる。
ハイレベルなAIサービスの一例として、画像キャプションサービスがある。このサービスは、画像の説明文(「プードルがキッチンの床で寝ている」など)を作成する。メインサービスは、画像内で識別されたオブジェクトの相対的な位置に基づいてキャプションを作成することが可能である。このサービス自身はオブジェクトを識別しないが、その代わりに下位のサービスを呼び出して識別し、その情報を使って画像のキャプションを作成する。
4.1.3 より高度なAIサービスが成長の原動力となる
AIアルゴリズムに特化した低レベルのサービスが、日常の問題解決にどのように適用できるかは、すぐにはわからないものです。そこで役立つのが、より高度なサービスです。このサービスは、ドメイン固有の問題を解決するツールへの便利なインターフェースを提供します。このようなハイレベルでユーザーフレンドリーなサービスが多ければ多いほど、SingularityNETの活動は大きくなると考えています。
図12.SingularityNETのフライホイール
この関係は上の図12に示されており、青いフライホイールはSingularityNETのアクティビティ、つまり、サービスが呼び出される頻度を表しています。フライホイールが速く回れば回るほど、青い円は大きくなり、ネットワーク上のアクティビティのレベルを反映します。フライホイールの周りに表示されているアクションが、フライホイールの回転速度を動かします。左上から順に、ネットワーク上のAIサービスの選択肢が増えれば増えるほど、AIプロジェクトの選択肢も広がり、より高度なAPIが作成されることになります。これは、より良いユーザー体験が得られ、その結果、ネットワークへのトラフィックが増加します。このトラフィックは、ネットワークにAIサービスを展開する開発者をより多く惹きつけ、このサイクルが続く。
この活動により、SingularityNET Foundationはプラットフォームとインフラに投資するための追加資金を得ることができ、その結果、スピードと信頼性を向上させることができます。この結果、スピードと信頼性が向上し、ユーザー体験が改善され、プラットフォームへのトラフィックが増加することになります。
4.2 SingularityNET財団が提供するAIサービス
シンギュラリティネット財団におけるハイレベルなAIサービスに関する最初の取り組みとして、私たちは4つの重点分野を選択し、以下に中程度の詳細を説明します。
● ネットワーク解析
● ソーシャルロボティクス
● バイオデータ解析
● 確率的グラフィカルモデルとシリアスゲーム
4.2.1 ネットワーク解析
4.2.1.1 モチベーション
ビッグデータの時代は、「ネットワークの視点」、つまり、物事と物事の間のつながりは、しばしば物事そのものと同じくらい興味深いということを教えてくれました。ネットワーク分析には、ネットワークという視点を持ち、大量の情報の中から意味のあるストリームを吸い上げるための幅広いツールが含まれます。SingularityNETで構築しているツールは、以下のような分野を扱っています。
● ソーシャルネットワークの解析と可視化では、数学のグラフアルゴリズムを用いて、ネットワーク全体の形や中心性などの部分の特性を記述する。これにより、例えば、ネットワークのメンバー同士のコミュニケーションの度合いを見たり、最も影響力のあるコミュニケーターが誰であるかを推測したりすることができます。
● 確率統計のアルゴリズムを用いて因果関係を記述することで、例えば、人々が最も訪問したいと思うWebページや、患者について知っているすべての事実がある場合の最適な治療方法などを知ることができる確率的グラフィカルモデル。
● ネットワークの進化:時間の経過とともにネットワーク関係がダイナミックに展開する様子を、進化計算とネットワークの結果を生成・予測するニューラルネットワークを使って研究している。特に、ネットワークの成長と衰退を引き起こす要因に注目し、例えば、特に競争の激しい市場で来年はどのような商品やサービスが求められるかを予測することができます。
● ネットワーク型人工知能、分散型人工知能プログラム間の協調的・競争的なつながりと、これらのアルゴリズムがより良い解決策へと自己組織化するプロセスを研究するものです。私たちは、分散型人工知能の原理を、SingularityNETのダイナミクスを設計するためだけでなく、人間の労働力を節約し、AIプログラムをより効果的に顧客に提供するためのツールとして活用しています。
● 複雑適応系のエージェントベースシミュレーションは、実世界のシステムにおける好循環と悪循環のフィードバックサイクルをエミュレートし、目標達成のための最適な政策を見出すものである。例えば、社会における汚職の悪循環を断ち切る方法を探ったり、住宅市場がバブルであることを知らせるアラートを開発したり、ロボットのソフィアで象徴的相互作用論的社会フィードバックをエミュレートしたりすることができるだろう。
4.2.1.2 応用例
応用分散型人工知能の専門家が、様々なネットワーク解析ツールを開発し、それぞれ実用化されています。これらには以下のようなものがあります。
● 人工知能モジュール間のフィードバックにより、AIアルゴリズムの選択とパラメトリック化の人的労力を軽減するツール。モジュールは、そのモジュールに固有のテストと、その消費者が設定したテストなどで評価される。AIプログラムのクラスによっては(例えば、クラスタリングやベクトル空間などの教師なしアルゴリズム)、これらの複数の弱いテストは、1つの強いテストよりも効果を測定することができる。
● データをアプリケーションに落とし込む際の人間の労力を軽減するための自然言語ツールです。このツールは、自然言語のテキスト(医学研究論文など)を、人間が理解でき、かつ下流のAIが必要とするように解釈する。教師あり学習技術で必要とされる大規模なリストではなく、少数の模範となるものを用いて、ネットワーク化された関係を使って、教師なしのクラスタリング装置を人間が設計したオントロジーに誘導するように設計されている。
● AIエージェントにミクロレベルの社会心理現象(認知的不協和や象徴的相互作用論など)をエミュレートさせ、これらのミクロな行動がマクロな社会パターンをどのように作り出し、反応するかを探る社会政策検証ツール。社会悪に対する治療方針は個々のエージェントに適用され、そこでエージェント間の相互作用への影響を観察し、治療法を探ることができる。このツールは、集団の分極化を引き起こすハイブリッド戦争キャンペーンに対する防衛戦略の開発や、社会の腐敗を緩和する政策の開発に適用され、受賞歴のある分析によってそれを実現している。
● 確率的オントロジーの知的ファブリックを用いて、複数の異種シミュレーション現実の出力を一つのまとまった全体として結合するツールで、各現実における手の入力を自動化し、手の結果を評価するためにゲームツリーの先のモデルを実行する。このツールは、大規模な社会システムの分析に適用され、賞を受賞しており、あらゆるデータ融合アプリケーションに有用である。
● 適応型経済エージェントを組み込んだ市場テストツール。保険会社からの依頼で、Affordable Care Actのもとアメリカの医療の質を高めるための支払い改革の効果を検証し、高次効果を含む分析により、特定の市場における新規事業の最適な価格設定と提供方法を見出すために使用されました。
● 実世界のデータをゲームとして遊べる形に変換し、人工知能の技術で最適化するツール。このツールは、医療費請求データを用いて、治療効果の見込みをマッピングする個別化医療に応用され、ディープニューラルネットワークの精度と、データの因果関係をからめ取る疫学アプリケーションの能力を併せ持つ。
4.2.1.3 SingularityNETシミュレーション
このミニチュアSingularityNETは、レピュテーションシステムなどのSingularityNETの「ポリシー」設定のテストと、完全なSingularityNetと同じ種類の分析を、分析者のパーソナルコンピュータで実行できるミニチュアとして提供するという2つの目的で、ネットワーク理論の抽象化を使って設計・構築しています。
このミニチュアSingularityNETは、プログラムが価格シグナルを通じて互いにフィードバックを送ることができる小さな市場である。価格シグナルは信用の割り当てとして機能する。このシミュレーションでは、Pythonのプログラム、モデル、AIを共進化させることができます。あらゆる共進化の目的に利用することができる。
このシミュレーションでは、個々のエージェント以上の創発的な認知特性を持つエージェント間の認知シナジーの様相を示しています。
このシミュレーションモデルでは、エージェントに様々なAIプログラムを実行させることができるため、現実的なSingularityNETをシミュレーションする以外にも、様々なことを行うことが可能です。例えば、すべてのAIエージェントがクラスタリングアルゴリズムを実行しているSingularityNETをシミュレーションすると、シミュレーションされたSingularityNETは実質的に創発レベルのクラスタリングメタアルゴリズムとなります。
クラスタリングや予測といった様々なAIタスクや、政治システムや実世界の市場のモデル化といった実世界のシステムモデリング・タスクを、特定の方法で設定・分散された実際のAIアルゴリズムを実行する模擬エージェントで構成される特異点網を作るという手法で実施することができます。この方法は、あるAIエージェントのモデリング・プロセスが、他のAIエージェントのモデリング・プロセスからのフィードバックによって恩恵を受けるような状況で、特に効果的に使用することができます。
例えば、データの解釈と、そのデータを生成したプロセスに関する複数の異なるモデルが重なり合うことで、データとモデルが一体となってより良いモデルを作り上げるというような応用が考えられます。このようなフィードバックによるデータフュージョンの研究では、フィードバックを受け入れ、調整するように設計された特別なデータ処理装置とモデルを使っています。例えば、模範的な入力を取り込むことができるクラスタリング装置や、理論とデータを統合する特殊なデータ吸収特性を持つエージェントベースモデルなどである。同様のアプローチは、共進化ニューラルネットワークのような、より洗練されたAI手法でも可能であり、ニューラルネットワークの一部を他の種類のAIと一緒にコネクショニスト・エコシステムに組み込んでいる。
4.2.1.3.1 ソーシャルメディア
ソーシャルメディアのアルゴリズムは、現代の社会問題の多くを引き起こし、自然な社会的相互作用の代用品としては不十分であると疑われていますが、現代のビジネスにとって不可欠なものであることに変わりはありません。
ソーシャルメディアのエグゼクティブにとって最も重要なことは、ビジネス、社会、文化、政治的な交流の質と実用性をいかに維持するかということですが、ソーシャルメディアのアルゴリズムが社会の構造にどのような影響を及ぼすかについての科学は十分に発達していません。
人工的な社会環境がデジタル空間に構築されるとき、そのルールやアルゴリズムは現実世界での社会的相互作用を支配するルールの代理、代用となる。例えば、SingularityNETのレピュテーションシステムは、人々が誰が権威的で注目に値するかを判断する方法のアルゴリズム的代理人です。
私たちは、技術の方向性が痛みを伴うことは避けられないと仮定するのではなく、社会的代理人を改善することによってどのように痛みを回避できるかを模索し、特に、人々が互いを知り、互いから学ぶことを助けながら人々を保護する自然な社会的相互作用の特質を見極めようとしているのです。
社会科学からの洞察を用いて自然な社会的相互作用をシミュレートし、それを複数のソーシャルメディアや社会的代理アルゴリズムと比較する。民主的な実力主義や経済成長といった社会的価値の尺度を作成し、ソーシャルメディアのソーシャルプロキシアルゴリズムと比較検証します。
特に、人気のあるクラウドソーシング・アルゴリズムが新興の寡頭政治に与える影響をテストし、民主主義を守るための方法の代替案を探っています。SingularityNETの研究者であるDuong博士の受賞歴のある社会科学政策テストの歴史は、SingularityNETで我々の評価システムをテストするために使用されています。
私たちはこれらのテストを拡張して、公正さ、つまりすべてのソフトウェアにそのメリットに比例して選ばれるチャンスを与える能力など、SingularityNETの価値を測る指標を含めたいと考えています。また、SingularityNETの成長段階に応じて、評価システムをどのように変化させるべきかを検討しています。
我々は、ソーシャルネットワークにおける寡占とそれに関連するダイナミクスの同じモデルを、SingularityNETの価値を始め、一般的な社会的ニーズを満たすソーシャルメディアアルゴリズムの能力のテストと測定に拡張します。特に、民主主義と実力主義をアルゴリズムで促進することで、より良い製品が生まれることを実証しようとするものである。
4.2.2 ソーシャルロボティクス
4.2.2.1 モチベーション
私たちのソーシャルロボティクス研究トラックは、自然なインターフェースと人工知能の使用により、人間の幸福度を向上させることに焦点をあてています。人間の行動や社会を技術に適応させるのではなく、人間の自然な行動に合わせた技術を適応させ、社会的かつ文化横断的に直感的なインターフェースを作り上げるものです。私たちは、具現化された人型ロボットや仮想アバター(ヒューマノイド)を研究開発することによって、これを実現することを目指しています。
SingularityNETの共同設立企業の一つであるHanson Roboticsは、人と自然に対話できる人型ロボットに注力しています。SingularityNETとHanson社は、AIサービスやアプリケーションを提供するための次世代インターフェースとして、複数の種類のロボットを育成するシステムを設計し、グローバルな人工知能の出現を促しています。
AIは、これらの技術をいくつかの重要な方法で推進します。
ディープラーニング、機械学習、コンピュータビジョンモデルにより、人間のインタラクションの聴覚と視覚の理解が可能になります。正確な知覚は、すべての社会的相互作用の根幹であり、人工ヒューマノイドとの相互作用の質と流れを形成します。
このトラックでは、社会的な手がかりを知覚することに重点を置いています。また、データ収集とモデリングの両方において、包括的かつ異文化間の研究を提唱する。また、人がどこを見ているか、誰を見ているか、誰に向かって話しているか、視線や姿勢など、人と人との関係を理解するためのトレーニングにも関心があります。最近の視聴覚知覚の進歩はディープラーニングの分野で多く見られますが、私たちは人間とヒューマノイドの相互作用のあらゆる側面を通してデータを収集するという総合的なアプローチで貢献できると考えています。
このトラックでは、知覚だけでなく、音声合成、ボディジェスチャー、顔の動きなど、ヒューマノイドの動作に関する研究も積極的に行っています。音声合成では、現状よりも感情表現が豊かで、様々なイントネーションが可能な音声合成の方法を開発しています。また、ヒューマノイドエージェントに特化しているため、データ駆動型の表情モデルや表情ミラーリングにも力を入れています。
我々は、GHOST フレームワーク(5.2.6 節で説明する General Holistic Organism Scripting Tool)内で開発された対話・行動エンジンを構築している。このエンジンは、OpenCogの認知アーキテクチャを利用して、データ駆動型の知覚・表情モデルとヒューマノイドの振る舞いを統合することを目的としています。しかし、この設計・開発の最初の段階でも、知識表現の共有とAtomSpace内の緊密な統合により、従来のターンベースシステムよりも緊密にすべてのコンポーネントを統合することができます(5.2.7節)。研究開発の過程で、ルールベースの側面を、言語学習、PLN、ECANなど、SingularityNETの他の研究分野で開発されたより高度なアルゴリズムにどんどん置き換えていくことを目標としています。
4.2.2.2 応用例
続いて、上記で紹介したソーシャルロボット関連技術の応用例を紹介します。
Loving AIプロジェクトは、親切で愛情深いヒューマノイドの具象と対話することによる感情的な影響に関する研究でした。私たちはこの研究で、GHOST(5.2.7項参照)と私たちのemotionrRecognition deep neural networkと組み合わせて、ロボットのSophiaを使用しました。17我々は、2017年に香港(N=26)、2018年にサンフランシスコ(N=35)でIRB承認された研究試験でこの構成を使用しました。予備的な結果は、相互作用、具体的には視聴覚コンポーネント、感情に反応する対話、顔の表情ミラーリングを用いたガイド付き瞑想セッションが、幸福度の向上とよりポジティブな感情をもたらすことを示しました。また、この結果は、純粋な音声ベースのインターフェースよりも、人型ロボットや視聴覚アバターがより効果的であることを示唆しています。
General Holistic Organism Scripting Tool (GHOST) は、Mozi 計算生物学プロジェクトにおいて会話エージェントとしても使用されています。そこでは、制約のある、しかし自然な言語での対話を通じてユーザーを導くために、手作りのルールベースが書かれています。この会話エージェントと、プロジェクトで使用されている実験装置とのインターフェースとして、いくつかの重要なコンポーネントが開発されました。
4.2.2.3 計画
の主制御システムであるHEADに、OpenCogベースのGHOSTツールを統合しました。
人型ロボット「ソフィア」。18この統合システムは、現在、研究や
の開発、ソーシャルロボットの研究実験、そして公開イベントの一部をご紹介しています。
現在、スキルや自由形式のダイアログを構成的にデザインできるように、ルールベースに新しい目標指向の構造を追加する研究を行っています。また、開発プロセスにおいて、個々の能力およびアーキテクチャ全体の単体テストを行うための戦略を開発し、アーキテクチャを改良しています。
次のステップは、教師なし言語学習イニシアティブ、PLN、ECAN、その他OpenCogやSingularityNETのコンポーネントを用いて、ルールベースの構造をより深い認知的理解へとどんどん置き換えていくことです。また、このプロジェクトでは、SingularityNETでホストされているサービスをどんどん統合していきます。
4.2.2.4 サービス内容
ソーシャルロボティクストラックで開発中の具体的なAIサービスには、以下のようなものがあります。
17https://arxiv.org/abs/1709.07791。
18https://github.com/opencog/ghost_bridge
アクション
対談
● OpenCog AIをベースにした対話エンジン「GHOST」。
表現方法
● 表情生成
パーセプション
ビジュアル
● 顔
● 顔認識・追跡
● 顔認証
● 視線追跡
● 顔の表情と感情認識
● ビジュアルスピーキング&ノンスピーキングディテクター
ボディ
● ポーズトラッカー
● ロバストな人物検出
● ジェスチャー認識
● 歩容の特徴
聴覚
音声
● 音声認識
● 音声認識
● 音声アクティビティ検出
● 笑いの検出
● 多人数音声分離
● どの言語が話されているかの検出
4.2.2.5 マインド・モデリングとラビングAI開発
現在、Loving AIパイロットプログラムを拡張し、OpenCogのAIシステムに無条件の愛に関連する新しい機能を追加する作業を行っています。これらの機能は、柔軟性のあるロボットやアバターであれば実現可能ですが、当面はソフィアを使って実験・検証を続けていきます。特にSophiaは感情表現が豊かで、世界的なメディアにも取り上げられており、我々のチームにとっても馴染みのあるシステムです。
2019年の作業は、OpenCog/Sophiaに初めて本物の「心のモデル」を与えることに焦点を当てます。目標は、AI/ロボットが、対話する相手の思考、感情、動機、意図などの実用的な内部モデルを構築することにある。そうなれば、ロボットが純粋に無条件の愛を表現するために必要な、対話する相手に対する理解が大きく深まると考えています。もちろん、この最初の「心のモデル」は、典型的な人間の他の人間の心のモデルと同じにはならないでしょうが、この重要な方向へのスタートにはなるでしょう。
この研究の動機のひとつは、Loving AIプロトコルを拡張して、AIが対話しながらその人について学習し、その学習をある程度、その人への発言や質問に生かせるようにするための土台を作ることです。これにより、ロボットがその人物のモデルを構築し、改善しながら、同じ人物と継続的にセッションを繰り返すことができるようになるのです。
このマインド・モデリングは、AIフレームワークの感情制御を活用・改善した結果、感情モデリングを統合し、AIの感情がモデルとなっている人間の感情をよりよく反映・反応することを可能にします。これにより、Sophia(およびソフトウェアが制御する他のロボットやアバター)は、より豊かな感情表現、他者とのより良い感情的つながり、そして人間の感情全般の理解の始まりを得ることができるのです。これらはすべて、無条件の愛を表現し、最終的にはそれを感じるための「巧みな手段」へのステップなのである。
4.2.2.6 深層リカレントニューラルネットワークによる社会認識
現在の社会的認知の研究では、深層リカレントニューラルネットワークの力を使って、認知的不協和の状態を含む社会的な精神状態を表現し、情報に対する人間の反応を測定・予測し、その結果を人に送るメッセージの改良に応用しています。その結果、人間の認知的不協和や部族主義を利用した心理操作の試みを自動的に検知して警告したり、リトル・ソフィーというロボットと “親 “との間のフィードバックなど、個人レベルでのリアルな社会的反応をシミュレートすることができるようになりました。私たちの研究者はもともと、ボルツマンマシンを使って、情報操作に対する集団の反応をシミュレートする同様のプログラムを書いていました。このツールは、個人であれ集団であれ、複数の不協和音の可能性のある社会的情報メッセージがあるあらゆるケースに適用することができる。
4.2.3 バイオデータ解析
4.2.3.1 モチベーション
生物医学研究によって生成される実験データの量と複雑さが爆発的に増加していることは、広く認識されている。[19]ゲノム解析で日々生成されるデータ量は7ヶ月ごとに倍増しており、今後10年以内に、ゲノム解析では年間2〜40エクサバイトが生成されると考えられています。[20]
このため、新しい発見を臨床応用に結びつけるボトルネック[21]、いわゆる「トランスレーショナル・メディスン」のパイプラインが形成されており、機械学習やその他のAIアプローチを適用してデータ処理の速度を上げ、このギャップを埋める必要があると広く理解されている[22]。22 データを処理・保存し、理解しやすい形で分析・要約し、正常・病的プロセスの包括的な予測モデルに統合し、これらのモデルを患者の診断・治療に適用するためのソフトウェア基盤が必要である。[23]
4.2.3.2 応用例
体系的な知識発見。文献収集とテキストマイニング
科学論文の数が指数関数的に増加する中(世界の科学論文は9年ごとに2倍になる24 )、手作業による知識の収集とキュレーションは非常に困難な作業となっている。研究機関のネットワークは、手作業と様々な自動化された手法の両方を用いて、数千の知識ベースに新しい知識を継続的に集約しています。一つの実験から数千から数百万の異なる測定値が得られるが、研究中の現象を説明する因果関係の仮説を構築するために、これらの既存の知識を参照しながら選別しなければならない。AIを生物医学研究に応用する上で、科学文献や実験結果の検索を自動化することは非常に重要な目標である。
19https://www.cnbc.com/2015/12/10/unlocking-my-genome-was-it-worth-it.html、https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4955563/、https://www.liebertpub.com/doi/full/10.1089/big.2014.0023。
20h ttps://www.washingtonpost.com/news/speaking-of-science/wp/2015/07/07/sequencing-the-genome-Creates-so-
much-data-we-dont-know-what-to-do-with-it.
21https://www.nature.com/news/medical-genomics-gather-and-use-genetic-data-in-health-care-1.15065。https://ieeexplore.ieee.org/abstract/document/8123845。
22https://content.iospress.com/download/bio-medical-materials-and-engineering/bme1488。https://www.ncbi.nlm.nih.gov/pubmed/16207526。
23http://ieeexplore.ieee.org/document/8123845。
24 http://blogs.nature.com/news/2014/05/global-scientific-output-doubles-every-nine-years.html。
系統的な知識発見。細胞集団と器官レベルのインシリコモデリング
インシリコ実験・解析では、数理モデリングやコンピュータシミュレーションを用いて、in vivoやin vitroの手法の様々な限界を克服し、バイオメディカルや製薬業界のニーズや研究課題をサポートします。経験則と物理学に基づいたインシリコモデルにより、新規の遺伝・代謝ネットワークの予備的発見と実験での検証が可能です。ゲノムスケールの代謝ネットワークの再構築プロセスはよく開発されているが、手間がかかる。Thiele と Palsson[25] は、この分野の研究において最高のプロトコルを発表した。
しかし、計算生物学や化学の目覚しい発展にもかかわらず、組織や器官レベルのシミュレーションの数は限られています。今のところ、マウスの膵臓、線虫の生殖腺、ネズミの脳の部分的発生の3つの臓器しかインシリコでモデル化されていない。[26]
一方、PhysiomeプロジェクトやVirtual Physiological Humanイニシアティブで開発された人体生理学モデルなど、すでに臨床問題の解決に応用され、インシリコモデリングを臨床応用に近づけているモデルもあります。[27]
診断用バイオマーカー探索
バイオマーカーは、生物学的状態や健康状態の変化を示すものです。新規バイオマーカーの発見とDNAマイクロアレイや質量分析などのハイスループット技術の進歩は、観察・分析疫学、臨床試験、スクリーニング、診断、予後予測に直接的な支援を与える。測定・評価目的や生物医学データに基づく予測モデル構築のために、多くの統計学的手法や機械学習手法が採用されてきた。
創薬ターゲット探索
生物医学における大きな課題の一つは、合理的な薬物設計とターゲット指向の医薬品開発のために、疾患の代謝・調節経路を特定することである。代謝ネットワークのインシリコシミュレーションにより、これらの予測された遺伝子型-表現型-薬物代謝経路を模擬的に検証することができます。
パーソナル/プレシジョンメディシンの診断と治療計画のためのインシリコ患者モデリング
未来の医療は、患者一人ひとりの生物学的な設計図に全体的に対応する、高度にパーソナライズされたものになるでしょう。科学は、機械学習ツールを使って個人のゲノム、プロテオミクス、その他の「-omics」の完全なアトラスを構築することにより、各人の生物学的構造のユニークなダイナミクスを明らかにし始めている。個人のマイクロバイオームとゲノム、メタボローム、エピゲノムを結びつける強力なモデルにより、以下のことが明らかになりつつある。
25https://onlinelibrary.wiley.com/doi/book/10.1002/9781118617151.
26https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3896968/。
27https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3055650/。
これらのつながりを完全に理解することができれば、正確な診断技術と高度な標的治療(いわゆるセラノスティックス)を結びつけることができ、インパクトのある治療薬を生み出すための成功戦略を開発し、「医療を反応から予防へ、病気から健康へ」と転換することができるようになるでしょう。[28]
図13.デジタル患者を開発・維持するための主な重点分野[29]
28https://onlinelibrary.wiley.com/doi/book/10.1002/9781118952788.
29画像はThe Digital Patient, (2016), doi:10.1002/9781118952788 より引用。
4.2.3.3 サービス内容
バイオデータトラックで開発中の具体的なAIサービスは以下の通りです。2019年2月のSingularityNETのベータ版でリリースされるものもあれば、継続的な作業を踏まえて後日リリースされる予定のものもあります。
MOSESによる2値データの教師あり分類
SingularityNETエージェントは、データファイルと分類ラベル情報、プログラムアルゴリズムと検証パラメータを受け取り、スコアリングされたコンボモデルのファイルとモデル特徴のランク付けリストを返します。
MOSESを用いたSNPおよび遺伝子発現データの教師あり分類のためのユーザインタフェース
ウェブベースのインターフェースは、カテゴリラベルを含むデータファイルの入力を受け付け、アルゴリズムと検証パラメータを設定するインターフェースを提供し、オプションでイーサリアムウォレットアドレスを募り、(1)のMOSESエージェントが生成したスコア付きコンボモデルとモデル特徴のランクリストを含むファイルを返送します。
AtomSpace知識ベースを用いたMOSESの結果や他の遺伝子セットのアノテーション
Webベースのインターフェースは、遺伝子名または参照IDのリストを受け取り、オプションで参照知識ベース、アノテーションタイプ、およびフィルタリングパラメータのリストから選択する画面を提供し、入力遺伝子とそのアノテーションの表および/または入力遺伝子とそのアノテーションのグラフ表現を選択した標準グラフフォーマットで返す。
遺伝データセットへのシンボリック回帰
SingularityNETエージェントは、遺伝的および数値的バイオマーカーデータセット、各サンプルに関連する数値結果値、およびプログラムアルゴリズムと検証パラメータからなる遺伝データパッケージを受け取ります。そして、その遺伝子データパッケージに対応する表現型番号を予測するモデルを含む結果ファイルを出力します。オプションとして、FFXまたはMOSESアルゴリズムのいずれかをユーザが指定することができます。
結果セットや知識ベースへの問い合わせのためのテキストユーザーインタフェース
GHOSTをベースにした自然言語クエリパーサ(5.2.6節で説明)は、AtomSpace(OpenCogのデータベース標準、5.2.7節で説明)を入力として、選択した知識ベースと解析結果を、文脈に依存したクエリとして利用できるようにする。
MOSESを用いた変異体/SNP投与量レベルデータの教師あり分類
MOSESのインターフェースは、全ゲノムバリアントデータの前処理や、対立遺伝子量を示す特徴変数フォーマットを容易にするために拡張される予定です。
AtomSpace知識ベースを用いたバリアント/SNPリストやその他の遺伝子ベースレベルのデータへのアノテーションフィーチャーアノテーションサービスは、カスタムAtomSpace知識ベースを通じてアノテーション可能な、オプションの対立遺伝子用量を持つバリアント/SNPリストへと拡張され、オープンソースのバリアントアノテーションサービスコードが https://github.com/DEIB-GECO/GMQL および https://github.com/bulik/ldsc に組み込まれる予定である。
配列-発現リンクのニューラルネットモデリング (既存のオープンソースコードをラップする)
配列/変量フィーチャー形式を用いて、配列と組織型を入力し、ニューラルネットモデルから転写産物の発現を予測します。
https://github.com/FunctionLab/ExPecto。
バイオNLP 文章関係抽出
バイオエンティティ(低分子、遺伝子、タンパク質、細胞型、生物、病気など)にタグ付けする既存のオープンソースツールを使い、OpenCog自然言語処理ツールは任意のプレーンテキストやPDF文書からそれらの関係を抽出し、その関係をAtomSpace表現として出力します。AtomSpaceの知識ベースは新しい情報によって更新される。この知識ベースは、ユーザー調査に関わるデータマイニングや推論処理に有用である。
モデル生物知識ベースからの転移学習
遺伝学における主要な課題の一つは、遺伝子やタンパク質の機能を予測し、その制御経路を特定することである。データマイニングといくつかの機械学習技術は、生物間で遺伝子アノテーション情報を転送するために成功裏に適用されている。
AtomSpace知識ベースとゲノムスケール細胞代謝モデルを用いたML結果からの細胞レベル仮説生成
バリアント、転写産物発現レベル、タンパク質量の特徴リスト、実験結果データからの細胞タイプやその他のコンテキスト、および公開または独自のカスタマーソースからの背景知識を含むAtomSpaceが与えられると、実験データに関連して観察された表現型を説明する因果関係の仮説が生成されます。
AtomSpace知識ベースと細胞外環境を含む細胞アンサンブルモデルを用いたML結果からの組織レベル仮説の生成
知識ベースコンテンツと推論ルールベースを細胞外および組織レベルのコンテキストと組み合わせることで、実験サンプル被験者の臨床および実験パラメータに基づく有意義な仮説駆動型推論を生成することができるようになります。
4.2.4 確率的グラフィカルモデルとシリアスゲーム
ディープリインフォースメント学習法は、最近AIで最も人気のあるアルゴリズムの一つですが、多くの理由から、これまでゲーム環境以外の本格的なアプリケーションは見つかっていません。私たちのグラフィカルモデルの研究では、ネットワークを実用化するための方法を模索しています。例えば、複雑な病歴を持つ患者に最適な治療法を見つける「ヘルスケアゲーム」や、実世界のあらゆるデータを扱うための方法などです。観察データの扱い方は、ルールが分かっているゲームの世界から、科学や疫学を通してルールを探る実世界への架け橋となるものです。
のテクニックを駆使しています。
グラフィカルモデルの研究では、実世界のプロセスをマルコフ決定過程(MDP)に変換し、異なる処理による実世界の状態の変化を表現することを目指しています。この形で表現すれば、強化学習AIなどで最適化することができる。しかし、このような形でデータを表現するためには、観測データからどのように因果関係を導き出すかに注意を払う必要がある。そのために、疫学的な概念(Pearlの「do」関数、道具変数、潜在的な結果の枠組みなど)と、新しい精度を持つディープニューラルネットワークの最近の開発を組み合わせています。
現在、この手法を政治運動に関する精選されたデータセットに適用しており、次は健康保険の請求データなどのヘルスケアデータに適用する予定である。しかし、これらは現在の実験の焦点ではありますが、潜在的な応用範囲は非常に広いのです。
SingularityNET AI研究開発の概要
SingularityNETが、垂直市場全体で優れたAIアプリケーションを育成し、強力で慈悲深い人工一般知能を播種するという目標を達成するためには、狭い範囲のAIアルゴリズムやサービスが顧客とマッチングする優れたマーケットプレイスであるだけではいけません。ネットワークには、抽象的で汎用的なAIタスクを実行するAIエージェントが一定の割合で含まれていなければなりません。このような低レベルのAIエージェントは、より用途に特化したタスクやエンドユーザー・ソリューションを提供する他のAIエージェントの下請けになることができ、特定の応用分野よりも一般的なルールを学習することができます。
この目的のために、SingularityNET FoundationのAIチームは様々なAI研究開発プロジェクトを進めており、多くの場合、すでに進められていたAI研究開発を継続・拡大することになります。
オープンソースコミュニティや大学で行われています。ここでは、そうした取り組みのうち、最も重要なものを紹介する。この研究開発の成果は、2019年から2020年にかけてSingularityNETでローンチされる予定です。時間が経つにつれて、知性と応用力を高めたコミュニティの貢献が期待され、財団から開発の重荷のほとんどが取り除かれることになるでしょう。
このような技術的・科学的な取り組みは、いくつかの点でユニークなものです。一握りの大手テクノロジー企業以外では、スケーラブルなソフトウェア工学と互換性のある方法で、同等の規模の深層AI研究が行われているところは地球上どこにもありません。さらに、大手テクノロジー企業が自社の膨大なデータを活用したディープニューラルネット技術に注力しているのに対し、SingularityNETの研究開発は、コモンズベースの認知アーキテクチャの中でAIを追求しているのです。
この研究開発作業から生まれたAIサービスは、そのサービスを自分のソフトウェア・プラットフォーム内で直接利用する方法を知っている高度なSingularityNETの顧客に直接価値を提供し、SingularityNETプラットフォーム上で動作する他のAIエージェントの下請けとして間接的に価値を提供することになるでしょう。そのようなAIエージェントはより高度な機能を備えていない可能性があり、SingularityNET財団のAIチームが作成したAIエージェントにクエリーを送信し、その機能を強化する必要があります。
5.1 はじめに
シンギュラリティネット財団のAI研究プログラムは、以下のような複数の既存の研究イニシアチブの組み合わせと交差を反映しています。
● OpenCog AGIプロジェクトは、SingularityNETのCEO兼共同設立者のBen Goertzel博士と同僚が、AIソフトウェア会社Novamente LLCでの以前の仕事を基に2008年に設立したものです。OpenCogの開発チームの大部分はSingularityNETのチームに参加し、SingularityNETのプラットフォームと完全に統合された形でOpenCogベースのインテリジェンスを最適に開発・展開しています。OpenCogの一般的な背景については、CogPrime Overview Paperや、Engineering General Intelligence Vol.1 と Engineering General Intelligence Vol.2という本をお読みになることをお勧めします。
● サンクトペテルブルグにあるITMO大学のアレクセイ・ポタポフ博士の研究室から生まれた、関連する別の研究プログラムです。これは、ディープニューラルネットワーク、確率的プログラミング、進化的学習を、共通の確率的学習ベースのAGI理論に統合したものです。ポタポフ博士は現在、SingularityNETのAI研究開発グループの中で重要なチームを率いています。
● ハンソン・ロボティクス社のAIチームとSingularityNETチームが共同で行っている、ロボットなどのAIキャラクターを制御するための知覚、動作、言語、感情理解、表現などの統合に関する研究。
● St.のSergey Shyalapinの研究室で行われている、深層神経回路網と数理言語学の融合による計算論的言語理解・生成に関する研究。
ペテルスブルグ、そして現在は言語学習のための確率的記号論的手法に関するOpenCogベースの研究と統合されています。
● デビー・ドゥオン博士とベン・ゲーツェル博士が2002年から2007年にかけてワシントンD.C.で政府資金による研究を行って以来、緩やかな共同研究を行ってきた複雑系のダイナミクスを分析・指導するAIに関する一連の研究、およびゲーツェル博士とブリュッセル自由大学の地球脳研究所が2001年に始めた共同研究で、地球脳研究所からKabir Veitas博士がSingularityNETチームの代表となり、研究を行っている。
● 香港のバイオインフォマティクス企業Mozi Health社(現在はSingularityNETの密接なパートナー)で行われていた、生物データなどの複雑な科学データを解析するために、進化的学習と確率的推論や統計的学習を統合したAIの研究です。
ここにまとめた研究分野のほとんどは、SingularityNETの研究ブログの記事で取り上げられており、ここでの扱いはより簡潔な要約となっている。現在、大手テック企業のAIを支配しているディープニューラルネットを超える高品質のアルゴリズムとアプローチを提供したいと考えています。
SingularityNET財団のAI研究開発チームの活動は、OpenCog認知アーキテクチャや学習と推論の数学的理論など、AI理論と認知科学の基本原則に厳密な根拠を置いています。このような基礎的な原理に従って慎重に計画することで、チームは実用的な価値を提供するAIサービスを実現すると同時に、善意の人工知能という長期的な目標に向かって突き進むことができるのです。
簡単のために、研究イニシアチブを、(i)AIアーキテクチャとアルゴリズム、(ii)SingularityNETネットワークの測定、モデル化、拡張の2つのカテゴリーに分けました。
しかし、この2つのカテゴリーで行われている作業は、概念的なレベルでもコードレベルでも重複しています。
5.2 AIアーキテクチャとアルゴリズム
5.2.1 記号的学習と推論
ニル・ガイスヴァイラー博士は、OpenCogフレームワークにおける記号学習と推論に関する先進的な研究開発を行うチームを率いています。この研究のハイレベルな動機と概念的背景は、「OpenCogフレームワーク内での内省的推論」や「認知的視覚的質問応答の実現」などの研究ブログ記事で紹介されています。
この研究では、OpenCogの統一ルールエンジン(URE)をベースに、論理エンジンPLN(probabilistic logic networks)、自動プログラム学習エンジンMOSES、OpenCogパターンマイナー、注意配分システムECANなど、複数のAIツールを共通のフレームワークに統合しています。
概念的には、機械学習/推論においてより高いレベルの汎化・抽象化を実現するために、反射型メタ学習と認知シナジー(異なる認知アルゴリズム間のウィンウィンの相互運用)を活用することが重要なテーマである。
5.2.1.1 スケーラブルな一般確率論理学
この分野の重要な取り組みの一つが、確率的論理推論に関するものである。論理的推論は1960年代からAI分野の中心的な研究対象であったが、現代の計算資源、データソース、理論的進歩により、論理的推論と確率的・統計的推論を複雑に統合することが可能になっている。
問題(定理)とその解(証明)を透明な形で関連付ける能力は、異種プロセスの相互運用7、機械理解と人間理解のリンク、深いレベルでの内省とメタ学習の実現といった複雑なタスクに特に適しています。
人工知能の「汎化」の部分は、パターン分析や「カーブフィッティング」に端を発するディープニューラルネットワークなどのAIよりも、論理システムが特に得意とするところです。
現代の推論システムは非常に洗練されているが、共通の欠点がある。すなわち、不確実な知識や推論を扱わないか、あるいは制限的、非効率的な方法で扱う傾向があり、推論を構築する際に固有の組み合わせ的爆発が起こるため、一般に非効率的である。
我々は、これらの欠点を克服(あるいは少なくとも軽減)するために、OpenCogフレームワークと連携して確率的論理回路網(PLN)を設計しました。
例えば、不確実性は数学的に厳密な方法で論理に組み込まれ、PLN推論者は最終的に論理学者と統計学者の両方の代用となることが可能である。さらに、その不確実性を厳密かつ一般的に扱う能力を再帰的に適用することで、PLNは自身の効率に関する問題(「推論制御」問題とも呼ばれる)を表現し解決することができる。
最後に、PLNが搭載しているエンジン、OpenCogフレームワークのユニファイドルールエンジンは、このような推論制御の知識が推論処理の指針となるように設計されている。
このように、自己改善のループを作ることで、最終的にはより効率的な推論が可能になります。
このビジョンを実現するためには、大きな課題があります。例えば、推論によってもたらされる透明性には、計算上のオーバーヘッドがある。さらに、それ自身の効率についての推論を可能にする初期の効率的な制御ポリシーをシステムに播くこと自体が困難である。最後に、システムが推論制御に関する知識を蓄積すればするほど、制御判断のコストが高くなる可能性がある。
OpenCogのアーキテクチャは、これらの課題に対応するために、本来普遍的でありながら、全く異なる長所と短所を持つコンポーネントの集合を提供し、相乗的に組み合わせられるように設計されています(コグニティブ・シナジーと呼ばれる原理)。
PLNに加え、これらのコンポーネントの一部をご紹介します。
● MOSESとは、meta-optimizing semantic evolutionary searchの略で、検索方法を学習する機能を内蔵した進化型プログラム学習器である。
● OpenCogの一般化されたハイパーグラフデータストレージであるAtomSpace上で動作する頻出サブグラフマイナであるPattern miner、および
● ECANとは、economic attention networksの略で、システムにおける知識やプロセスの重要度を動的に推定し、それに応じてクレジットを割り当てる資源配分システム。
私たちは現在、これらの構成要素それぞれについて、実用的な目標と理論的な理解の両方のためにどのように組み合わせるかについて研究しています。
5.2.1.2 確率的進化プログラムの学習と推論の統合
MOSESは、John Kozaの「遺伝的プログラミング」学習の枠組みをいくつかの重要な方法で拡張した進化的学習アルゴリズムである。
遺伝的プログラミングは、自然淘汰による進化の過程を模倣することで、コンピュータプログラムを自動的に学習させようとするものである。遺伝的プログラミングでは、プログラムの母集団を生成し、適性関数で評価する。不適合なプログラムは捨てられる。そして、最も適性のあるプログラムが生き残り、結合・変異させられて新しい世代が作られる。新しい世代のプログラムも、同じように評価と淘汰が繰り返される。
MOSESはこのパラダイムを拡張するものです。
● プログラム空間」の異なる領域を探索することに焦点を当てた、プログラムのサブ集団の集まりを考えています。
● プログラムを新しい階層的な「エレガントな正規形」に置き換えることで、より効果的に解析することができる。
● また、突然変異と組み合わせに加え、どのプログラムが適合するかという確率的なモデルを用い、この確率的なモデルを使って新しいプログラムを生成する。
これにより、様々なケースで優れた学習性能を発揮することが示されている。応用例としては、ゲノムデータ解析、異種データソースからの金融予測、ゲーム世界における仮想エージェントの制御などがある。また、洗練されたフレームワークであるため、新しい応用分野ごとに大幅なカスタマイズが必要である。
MOSESの計算のほとんどは、明示的に推論という枠組みをとっていない。この選択により、効率は向上しますが、柔軟性は低下します。フィットネス関数は非常に効率よく並列に実行され、数百万の候補を数秒で評価することができる。しかし、その過程で多くの透明性が失われる。例えば、最良の候補プログラムだけがその後の分析に残されるため、計算の大部分は破棄される。
しかし、重要なのは、MOSESの計算の一部が推論として組み立てられている点である。探索空間の特定の領域を探索することが有益である確率を推論するのである。このような判断は、計算量に比べれば少ないかもしれませんが、MOSESの性能を引き出すためには重要です。
これらのアンカーポイントは、不透明な効率的計算と透明な全体的計算の間の橋渡しとなり、認知的相乗効果の恩恵を流入させる開口部となるのである。
MOSESとPLNなどの推論・学習との融合は、2005-2007年のMOSES誕生以来の計画であった。この融合により、現在よりもはるかに複雑なプログラムの学習が可能となり、AGIへの発展や、さらなる多様な応用が期待されます。
MOSESとPLNを効果的に連携させるため、現在MOSESを統一ルールエンジンに移植中です。重要な判断は推論として明示的にフレーム化し、それ以外は効率的で透過的でない計算としてカプセル化したままにしています。現在、PLNで使用するために統一ルールエンジンに存在する推論制御とメタ学習のための既存のメカニズムは、その後MOSESで使用できるようになります。
5.2.1.3 論理的超グラフにおけるパターンマイニング
OpenCog pattern minerは、データベースにおける頻出パターンや驚くべきパターンをマイニングする既存のツールを拡張し、複雑なハイパーグラフにおける頻出パターンや驚くべきパターンをマイニングするための独自の強力なエンジンを提供する。
ハイパーグラフは、あらゆる形式の関連知識を統一的に表現するためにOpenCogで使用されているデータ構造です。ハイパーグラフが普遍的なAI表現フレームワークとして価値がある理由については、こちらのブログ記事をご覧ください。
パターンマイニングは最近、スケーラビリティとコンフィギュラビリティを高めるために、統一ルールエンジンの上に再実装されました。自然言語データ、マルチオミクス生物学データ、交通データ、金融市場データなど、複雑かつ不均質な構造を持つ大量のデータを扱うときに威力を発揮する。これらの分野では、リレーショナルデータベースや特徴ベクトルのような単純な表現よりも、論理的なセマンティクスを持つハイパーグラフの方が効果的である。
パターン・マイナーの最も深い用途の1つは、PLNのようなAIアルゴリズムの最適化です。これは、AIアルゴリズムにおける選択肢の中から、一貫してより良い結果をもたらすパターンを探すことで実現します。
例えば、PLN推論の実行中に統一ルールエンジンが残した全ての決定のトレースがあれば、パターンマイニングを適用して、コンテキスト、解決すべき問題、これまでに構築された推論、およびシステムの公理を理解することが可能である。そして、パターンマイニングは、ルールを適用して推論を構築し、与えられた推論が問題解決に向かうかどうかを評価する。
パターン・マイナーでは、推論エンジンの活動記録から、驚くほど頻度の高い超グラフ・パターンを抽出する。これらのパターンを用いて、将来の推論を高速化する重要な推論制御ルールを生成することが既に可能である。我々の最近の研究により、これはすでに効率的な推論を獲得するための複雑なプロセスへの出発点として機能することが示されている。
5.2.1.4 非線形な注意の割り当てによる推論の誘導
大量のデータや多数の認知プロセスを含むAIシステムでは、注意の配分が重要になる。OpenCogでは、ECAN(Economic Attention Allocation)と呼ばれるシステムでこれを処理し、ノード間で「人工通貨」のトークンを割り当てています。システムおよびその全体的な目標にとって短期的および長期的に重要な単位を表す知識ハイパーグラフのリンクがあります。
SingularityNETでは、ハンソンのAIチームと共同で、ECANフレームワークを大規模なAtomSpace上で動作させ、その注意の向け方が認知的に賢明で実用的に有効であることを検証することに多大な労力を費やしてきました。
ECANは今日、多くの実用的な用途を持っています。OpenCogがロボットSophiaのための自然言語対話を生成できるよう、OpenCogの注意を向けます。MOSESが生物学的データのモデルを学習してAtomSpacesに取り込むと、PLNはそこでデータを解析することができます。ECANは、このプロセスでPLNの注意を向けるのに不可欠です。また、UREのルールアプリケーションの全般的な指導にも欠かせないだろう。
優れた推論制御ルールを学習することは非常に重要であるが、ルールを最適に組み合わせるには多くの計算が必要なため、これを用いても推論制御は複雑化する可能性がある。もし統一ルールエンジンがあまりに多くの制御ルールを持ち、可能な限りの関連ルールを重み付けして最適な判断をしなければならないとしたら、審議のために不特定多数が一時停止し、システムを停止させることになるだろう。
幸いなことに、ECAN自体を改良するために推論を用いることもできる。ECANは、データとプロセスにどのように注意を向けるべきかを表現するヘブリアン・リンクのハイパーグラフを使用し、このハイパーグラフは推論に従順である。したがって、このヘビアンルールを生成することができるすべてのコンポーネントは、ECANを改善するために使用することができる。例えば、パターンマイニングは基本的なヘビアンルールを発見するために、PLNはより細かいものを発見するために使用することができ、MOSESも同様である。
5.2.2 統合的AIの事例としての統合ゲノミクス
生物学が情報科学となり、情報科学が機械学習やその他のAI手法に支配されるようになると、生物学がAIに支配されるようになるのは当然と言えます。病気や老化の全身的な性質に取り組むには、多数のデータセットにまたがる複数の身体のサブシステムに関するシミュレーション・モデリング、データ解析、機械的推論を行う必要があるのです。
この新たな医療のパラダイムは、システム生物学の大家であるリロイ・フッドによって「予測、予防、個別化、参加型であるP4医療」と呼ばれています。SingularityNETのCEOで共同設立者のベン・ゴーツェル博士は、この考え方を早くから実践してきました。2000年以降、彼は機械学習やその他のAI技術を長寿やゲノムに応用し、CDC、NIH、さまざまな大学と共同研究を行っています。
この精神に基づき、SingularityNET AIチームは、生物医学データ分析、特に長寿と加齢に伴う疾患に関するゲノムデータの分析を、OpenCogフレームワークに複数のAIパラダイムを統合するための最初の実験場として選びました。
MOSESは、ゲノムデータセット中のパターンを見つけるために使用されます。次に、これらのパターンを表現する小さなプログラムをAtomSpaceのハイパーグラフ表現に取り込む。次に、PLN論理エンジンを用いて、パターンをGene OntologyプロジェクトやMSigDBなどの生物学的オントロジーから得られた知識、およびOpenCog自然言語処理技術を使って生物学のテキストから抽出した知識と組み合わせて結論を導く。
例えば、長寿者のゲノムデータにMOSESを適用すると、どの遺伝子や遺伝子の組み合わせが長寿に最も大きな影響を与える傾向があるかを知ることができる。これらのMOSESモデルについて、PLNと推論を一緒に行うことで
、これらの遺伝子がどのように老化に影響を与えるかについての仮説を得ることができます。これは、実行すべき新しい実験を提案したり、病気の状態を特定したり、将来の病気や長寿を予測するための診断法を提案したりするための強力なツールとなり得る。また、従来の薬物療法やCRISPRなどの遺伝子治療の標的を発見するためにも応用できる。
2019年、SingularityNETバイオAIチームは、2018年の研究中にこれらの手法を使って明らかになった老化や病気に関する新しい発見を記載した一連の出版物を発表する予定です。 しかし、これらのAIの改良とプロトタイピングの演習は、これらの特定の結果やこの特定のサブドメインを超えた重要性を持っています。これらの手法は、Singularity Healthtech StudioプロジェクトのAIコアの一部として機能し、また、ヘルステック以外の一般的な適用可能性も持っています。
例えば、金融サービスにおいては、価格、出来高、グローバルマクロ、企業会計、ニュースセンチメントのデータを組み合わせて予測モデルを構築するMOSESの学習エンジンの価値が実証されています。金融テキスト分析ソフトウェアは比較的成熟しており、上場企業やその内部構造、外部との関わりに関する膨大な量の構造化データを利用することができます。SingularityNETの研究チームがゲノムAIの文脈で洗練させた手法は、Singularity Studioのフィンテックモジュールで重要な役割を果たすことになります。
5.2.3 セマンティックコンピュータビジョンのための神経-シンボリック統合
ニューラルネットは、1940年代後半からAI分野の一部となっているが、その人気は数十年の間に盛衰している。近年では、多層階層型ニューラルネット(ディープニューラルネットとして知られている)が、さまざまな種類のデータ、特に視覚データと聴覚データの分析に成功し、特別な人気を博している。
少数のAI研究者は、この特殊なツールが普遍的な実用的AIソリューションに、さらには人工的な一般知能のためのアーキテクチャに改良できると考えています。しかし、ほとんどのAI実務家は、コースによって異なる馬が必要であることを認識しています。ディープニューラルネットはある問題には最適なソリューションですが、他の問題(特に透明で記号的な推論を必要とする問題)には他のAI技術を必要とするのです。
論理エンジンやプログラム学習システムなどの記号的AIアプローチ(それぞれ1960年代と1980年代から開発されてきた)は、歴史的にニューラルネットワークとは異なる強みを発揮してきた。一般化や抽象化、(物理世界や言論・科学の領域での)プロセス計画、新しいハイレベルな仮説の策定などに優れている。
例えば、コンピュータビジョンの課題は、理論的には画素レベルから論理的に推論する課題として定式化できるが、その推論は絶望的に非効率的である。ニューラルネットはコンピュータビジョンのタスクに適用することで真価を発揮する。一方、ニューラルネットワークだけで自動定理証明器を構成することは考えにくい。
より柔軟で広範な知能を目指すと、記号的な要素と神経的な要素の両方の必要性が明確になる。最終的に、人工的な一般知能の開発にはハイブリッドなアプローチが必要になる可能性が高く、純粋な記号的認知アーキテクチャや純粋な創発的(サブシンボリック、ニューラル)認知アーキテクチャはほとんど存在しない。ほとんどのアーキテクチャは両方の要素を持っているが、記号とサブ記号のギャップは完全に埋まるには程遠い。
ニューラル・シンボリックAIの分野では、ニューラル・ネットワークとシンボリック・アプローチを組み合わせて、両者の長所を生かした統一的なAIシステムを構築するための方法論を探求しています。
アルゴリズム情報理論や確率的プログラミングなどのツールを用いたAI理論における最近の数学的進歩は、この統合を追求するための首尾一貫した概念的・形式的枠組みを提供するものである。SingularityNETのAIサイエンティストであるアレクセイ・ポタポフ博士は、この方向で理論と実践の両面から重要な研究を行っています。2018年にSingularityNETに参加する前の、サンクトペテルブルクのITMO大学での彼の研究室の関連する成果の一部はこちらをご覧ください。
深い神経-記号統合の必要性は、画像理解(あるいは意味-視覚)問題の例で見ることができる。一方、視覚は、記号的AIシステムへの入力を形成するだけの周辺モジュールと見なすことはできない。一方、深層学習に最も適した視覚領域でさえ、純粋なニューラル・システムでは、構図構造を捉え、推論を行うには不十分である(特に、透明で解釈可能な結果が望まれる場合)。
また、画像分類システムであっても、外部の知識グラフを利用することが可能であることにも留意する必要がある。視覚的な概念とその関係を学習する問題を考えてみると、ニューラルネットワークと記号モデルを統合することと、従来のニューラルネットワークの形式を修正することの両方が必要かもしれない。視覚的な質問応答(例えば、AIに「写真の猫は何を着ているか」と質問する)のようなタスクでは、ボトムアップの画像処理に統合された、よりトップダウンの構成的推論が必要となる。
5.2.3.1 視覚的推論
視覚的なシーンに関する推論は、記号的な帰納的情報処理と記号的な演繹的推論を必要とするため、困難である。
例えば、”この2つの椅子は似ているか?”といった質問にAIが答えるとします。この視覚的質問応答(VQA)には、画像解析のトップダウン制御が必要である。この制御は、単純な質問に対しては、その埋め込みを利用したニューラルネットワークの形で実装できますが、いくつかのVQAベンチマークでは、この方法では不十分であり、より構成的な制御メカニズムが必要であることが示されています。
大きな球体の左側にある茶色い金属のようなものの左側にある円柱の大きさは?」というような、より複雑な問いは、決まった大きさの埋め込みベクトルに詰め込むのは困難です。ボトムアップ処理でこのような問いにすぐに答えが出せるとは考えにくい。
視覚的な対話を伴うタスクには、一種の短期記憶が必要である。神経モデルは単純な対話の仕方を記憶することができるが、より複雑な構成構造を持つ対話には、記号的推論と記憶の両方がより適している。
最近のディープニューラルネットワーク(DNN)ソリューションのもう一つの問題は、CLEVRとCOCO VQAデータセットのように、異なるタスク、さらには同じタスクでも異なるベンチマークに対して異なるモデルを開発・訓練していることです。
視覚的推論の進歩は、ビデオ解析、ロボット工学、意味的画像・映像検索、拡張現実感、視覚補助システムなど、多くの実用的な応用が期待されています。
これらの要因から、SingularityNETチームはセマンティックビジョンと視覚的推論の問題に、認知アーキテクチャというレンズでアプローチしています。コグニティブアーキテクチャは作業記憶、長期記憶、知識表現、推論エンジンなどを備えた統合的なシステムで、さまざまなタスクの解決を目指します。
具体的には、演繹推論を行うために確率的論理回路網を持つOpenCog認知アーキテクチャを、知識ベースを維持するためにAtomSpaceを利用しています。VQAの場合、現在、OpenCogのリンク文法とRelEx2Logicモジュールを利用して、自然言語の質問をPLNのクエリに変換している。また、PLNが実行時に実行可能なニューラルネットワークモジュールも開発中である。主な研究テーマは、OpenCogとDNNを異なる視覚的推論タスクに共同で適用した場合の両者の制限を研究し克服することである。
5.2.3.2 概念・表現学習
視覚的概念学習は、表現学習と密接に関連するすべての意味的視覚タスクの主要な構成要素である。視覚的概念は、様々な推論課題を解決するために開発された多くのモデルにおいて、分類器(識別モデル)として学習される。
これらの識別モデルは特定のデータセットに特化しており、十分な学習データがあれば学習することができる。実世界の視覚概念に対しては、通常、ImageNetやVisual Genomeなどのラベル付きデータセットで事前学習される。しかし、これらのデータセットは視覚世界の多様性を全てカバーしているわけではなく、教師なし学習や一発学習のタスクは一般的な意味的視覚に対して非常に興味深いものである。
これらの課題を解決するためには、ほとんどあるいは全く監視することなく、分離され、意味的に分解された表現を学習することが不可欠である。これは通常、InfoGANsやβ-VAEのような生成モデルで行われる。しかし、生成モデルによって学習された表現は、識別モデルによって学習された表現に比べ、はるかに劣る。両者の長所を得ることが必要である。
例えば、意味的な視覚的概念を学習するためには、ある程度の監視が必要である。しかし、物体のクラスが相互に排他的でないこと(犬とラマは同じ哺乳類だが、同じペットではない)、物体が可変の属性で特徴付けられること(ラマは茶色でも毛深い)等から、これらの概念間の関係(リッチ表現とディスアンカレッジ表現の両方)の学習にはさらなる困難が伴う。
我々の研究は、これらの困難を解決し、視覚的推論パイプラインに対応する生成モデルおよび識別モデルを統合することを目的としている。これは、より少ない監視でモデルを学習し、異なる視覚的推論タスクだけでなく、他の分野の新しいデータセットにそれらを転送するのに役立ちます。
例えば、異なるカメラで撮影した重ならない複数の画像から人物を特定したいとする。あるデータセットで学習したモデルは、別のデータセットに適用すると性能が低下します。実際には、これらのモデルはラベル付けされたデータセットで事前学習され、ラベル付けが非常に高価であるか不可能な新しいカメラセットに展開されるべきである。識別モデルと生成モデルを組み合わせることで、人物を埋め込む変数や厄介な変数を分解することができ、この問題を軽減することができます。同じ問題-ラベル付きデータセットの不足と教師なし伝達学習の困難は、生物医学や他の多くのアプリケーションでも典型的であり、同じ解決策が適用されるはずである。
5.2.3.3 ディープニューラルネットワークにおける汎化・不変性
少ない例から視覚的な概念を学習するには、強力な汎化が必要である。そのためには、不変の主要な特徴や潜在的な変数を特定し、それらを可変の不都合な要因から分離する必要がある。残念ながら、生成モデルだけではこの問題を解決することはできない。なぜなら、ニューラルネットワークは学習セット内の関数を近似することは得意だが、それを超える関数を外挿することはできないからである。
例えば、ある回転角の範囲内で回転した画像を再構成するようにデコーダネットワークを明示的に学習させたとしても、その範囲外では失敗してしまうのです。
汎化問題に対する一般解を達成することに関心がある。空間変換に関する一般化は、空間変換器を用いてハードコーディングすることができるが、より興味深い問題は、未知の先験的な変換に対する不変性を達成することである。
強い汎化の問題はビジョン領域の外部にあるが、我々はより表現力のあるフォーマリズムを用いてニューラルネットワークの汎化能力を向上させる可能性に着目している。
例えば、生成的なカプセルネットワーク(CapsNets)やハイパーネットワーク(HyperNets)を研究し、ある種の変換を一般化する際に優れた性能を発揮することを示した。特に、通常の潜在コードと制御変数に異なるタイプの変動要因が現れるハイパーネットによる離散化表現の学習の可能性を研究している。
一般的に学習性能を向上させることに加えて、このような拡張は異なる特定のアプリケーションを持つことができる。例えば、変換のモデルが未知の場合、ハイパーネットは空間変換器の代わりに用いることができる。また、Faster R-CNNの特徴を反転させる(すなわち、そのためのデコーダを構築する)ためや、画像マッチングシステムを設計するために使用することもできる。
5.2.3.4 神経-シンボリック統合のためのフレームワーク
既存のモジュラーネットワークは、これらのネットワークを組み合わせている。しかし、それらは、各ネットワークが割り当てられたタスクを持ち、特定の深層学習フレームワーク(TensorflowやPyTorchなど)で実装された実行エンジンを含む、ハードコードされたタスク固有の方法でそうしているのです。これにより、これらのモデルは自動的にエンドツーエンドで微分可能となるが、一般性を犠牲にしている。
このようなフレームワークの中で、認知アーキテクチャ全体を実装することは難しいと思われ、神経認知アーキテクチャの開発は行われているものの、既存のハイブリッドアーキテクチャに比べれば、はるかに成熟していないのが現状である。
一方、ハイブリッドアーキテクチャにおけるニューロ-シンボリックの統合は、独自の課題を提起している。特に、OpenCogのPLNを用いた視覚的推論では、視覚的概念を基礎とする深いニューラルネットワークと最終的な答えの間に、一連の記号的推論ステップがあることを仮定している。これらのネットワークを学習可能にするためには、推論トレースによるエラーバックプロパゲーションを利用するか、これらのトレースをTensorflow、PyTorch、その他の深層学習フレームワークに「コンパイル」する必要があります。
SingularityNETチームは、最も一般的かつ効率的な方法を選択するために、さまざまな可能性を検討しています。
さらに、生成的なニューロシンボリックモデルは、さらに困難である可能性がある。このようなモデルの現在の例としては、変分オートエンコーダをベイジアンネットワークと組み合わせ、共同変分目的語を用いて学習させたものがある。しかし、ベイジアンネットワークの構造を学習するためには、異なる推論アルゴリズムが必要である。
確率的プログラミングは生成モデルを定義する一般的な方法である。しかし、ディープニューラルネットワークに対してスケールしないサンプリングに基づく推論を用いるか、パラメータ推定に勾配降下を用いるかのどちらかである。ハイブリッド推論のためのフレームワークが必要である。本研究では、確率的プログラミングにおけるサンプリングを記号的演繹によって導き、そのサンプリングを勾配に基づく学習や進化的学習と組み合わせて、統一的なフレームワークで推論することを検討する。
我々は、視覚的推論モデルを実世界の問題に拡張するためには、深い神経-記号統合が不可欠であると考えている。
そして、ドメインの知識をモデルに取り込むことができる。例えば、ブティックに設置されたVQAやビデオ解析システムが、商品(ハンドバッグ、スカーフなど)のカテゴリーが記載された商品カタログを用いて推論を行うことが想像される。あるいは、ユーザーのスマートフォンの画像を解析し、観光名所に関する記号的な知識を有効活用して視覚的な対話を支援するローマのAIツアーガイドを想像してみてください。
もちろん、視覚的推論だけでなく、自然言語処理など、構造同定とパラメータ最適化を同時に必要とするタスクにも、望ましい統一フレームワークは多く応用されるだろう。最も基本的な例は、語義誘導とカテゴリへの単語クラスタリングを同時に行いながら、単語埋め込みを学習することである。
5.2.4 教師なし言語学習
AIシステムが人間の言葉を豊かに理解することは、さまざまな実用的なアプリケーションや、人間から学び対話し、人間の文化や価値観を理解するAGIシステムの実現を目指す上で非常に重要である。
言語学という学問分野は、その歴史の大半において、言語構造を注意深く形式化することに重点を置いてきた(最も単純な例は、多くの人が文法学校で学んだ文型である)。しかし、インターネットの登場以来、統計学や機械学習ツールを使って大量のテキストデータからパターンを見つけ出す「統計言語学」の研究が盛んに行われるようになってきている。
計算言語学の分野では、人間の大学院生の手によって文型が与えられた数千の文のコレクションなど、特別に用意された言語資源に機械学習アルゴリズムを適用する「教師あり学習」に特に注目が集まってきた。しかし現在では、この手法の限界が認識され、大量の生テキストを見るだけで自然言語の扱い方を学習する「教師なし」手法に注目が集まっている。
この領域には多くの重要なアプリケーションがありますが、SingularityNET、そして以前からOpenCogで注目しているのは以下のようなものです。
● 言語理解。自然言語で伝えられる情報を、AI推論システムで操作可能な構造化された知識に変換する(質問応答や知識発見などのアプリケーションを可能にする)。
● 言語生成。AIが内部の知識やデータを人間の言葉で表現できるようなシステムの構築
● 対話。言語の理解・生成・推論を組み合わせ、人と目的を持った対話ができるシステムを創る
そのために、教師なし言語学習(ULL)、特に教師なし文法学習の分野で、英語やロシア語などの特定言語の大量のテキストを取り込み、そのテキストで使われている言語の文法規則を一覧にして出力するソフトウェアを開発するプロジェクトを進めています。
このソフトウェアは、強力な言語理解・生成・対話システムを構築するために必要なものの一部に過ぎないが、それでも重要な部分である。
従来の言語学や教師あり機械学習のアプローチでは、人間の自然言語の文法を十分に理解することができず、一般的な話題について非公式に対話できるチャットシステムや、研究論文の重要な内容を要約する科学者支援システムといった汎用的な自然言語アプリケーションをサポートすることができませんでした。これらの目標を達成するためには、根本的な進歩が必要であり、私たちはその実現に向けて順調に進んでいる。
5.2.4.1 教師なし文法学習へのアプローチ
私たちの文法誘導のアプローチは斬新で、複数のアルゴリズムと複数のAIパラダイムを組み合わせている。この手法の単純なバージョンを適用した初期の結果は、Bridging the Language Divideで説明されています。
重要なのは、文中の各単語の間に重みをつけてリンクを作成することである。最も単純なケースでは、この重みは単語間の相互情報値を反映し、学習コーパス全体におけるこれらの単語のすべての共起を調べることによって計算されます。単語がカテゴリーラベルを付与されている場合、重みはカテゴリー間の相互情報値を反映することができる。この値は、トレーニングコーパス全体でこれらのカテゴリーに含まれる単語の共起をすべて調べることによって算出される。
また、コーパス上で学習させたディープニューラルネット(またはその他の予測言語モデル)を用いて、文の文脈や文が出現する談話・文書全体の文脈を考慮した形で、2つの単語インスタンス間のリンクの情報価値を計算することも可能です。最近の計算言語学の文献には、非常に多様なニューラル言語モデリングツールが紹介されており、我々のチームは、このタスクにおいてどのツールが最も信頼できる性能を提供するかを実験している。
まず、文中の単語対の間の重み付きリンクを計算する。次にMST(max-weight spanning tree)構文解析と呼ばれる処理により、文にマッチし、かつリンク文法理論に従った有効な平面グラフであるという2つの条件を満たすグラフを見つけることができる。現在、OpenCog AtomSpaceで使用するためにSchemeで実装されたMSTパーサーを使用しており、関連する言語ノードとリンクはOpenCogアトムとして表現されています。
類似の性質を持つ単語からなるカテゴリを作成することがあるが、このとき、一部の性質はMST解析に基づいて計算される。特性の例としては、”多くのMST解析で単語「walk」に左にリンクされている”、”多くのMST解析でカテゴリ「C45」に左にリンクされている “などがある。
分類の結果は、リンク重み決定プロセスにフィードバックされ、MST構文解析の別のラウンドの入力として使用されることがある。
このようにMST構文解析で得られた木のコーパスには、意外なほど頻度の高いパターンが見出されることがある。これらのパターンはアルゴリズムが学習する文法規則を構成する。学習されるカテゴリの中には、より意味的なものと、より純粋な構文的なものがある。つまり、学習される規則は、純粋な文法的なものから構文・意味的なものまである。
この方法は、通常の文法的な英語だけでなく、ツイートやテキストメッセージのようなインフォーマルな英語にも適用することができる。また、生物医学研究の抄録などの専門的な英語のコーパスに適用することで、この種のテキストにおける言語の使い方を表す専門的な文法を得ることができる。
アムハラ語のように形態素が複雑で、個々の単語が複数の接頭辞や接尾辞、さらには接尾辞を持ちうる言語では、単語レベルだけでなく文字レベルでも同じアルゴリズムの論理を適用する必要がある。
5.2.4.2 確率的言語生成
上記の学習アルゴリズムにより、OpenCogのAtomSpaceにAtomのセットが構築される。これらのアトムは入力コーパスの構文構造(と限定的な意味構造)の確率的モデルを形成する。この確率モデルを用いて、同じ構造を持つ言語を生成することができる。
最も単純な方法では、この確率モデルから比較的直接的に文章を生成することができる。これは「確率的言語生成」の一種と考えられ、局所的には首尾一貫した、賢明で文法的な文章を生成するが、長く続くと高度な意味づけを欠くようになる。つまり、いくつかの文章を生成することはできるが、意味のある長い文書を生成することはできないのである。
確率的言語生成は、文の断片を与えて確率的アルゴリズムにその断片を完成させれば、質問に答えるのにも利用できる。このような文の例としては、”The best thing about New York is .”
よりエキサイティングで洗練されたアプローチは、確率モデルに適合し、さらに意味的制約を満たす文章を見つけることである。これにより、言語的に流動的で構文的に正しく、かつ指定された意味的内容の塊を表す文が生成される。
5.2.5 言語から論理への写像の半教師付き学習
教師なし言語学習(ULL)研究プロジェクトで追求している自然言語文の構文解析は、非構造化自然言語から構造化論理表現への変換作業の一部に過ぎない。あるレベルの意味論には到達するが、量詞、比較級、多引数関係など、より抽象的な意味論のレベルには到達できないのである。
関連する研究プロジェクトとして、構文解析を意味論理式の集合にマッピングする後続処理に焦点が当てられている。この問題は、主流の計算言語学ではほとんど扱われていませんが、(OpenCogの確率的論理ネットワークなどの)記号的推論エンジンを自然言語データや対話インターフェースに接続するために重要な問題です。
この10年間、OpenCogプロジェクトでは、自然言語から意味情報を抽出するための様々な取り組みが行われてきた。これは、OpenCogがその情報を基に推論し、世界の知識ベースを構築することを可能にするもので、relex、relex2frame、relex2logicなどがある。これらの取り組みは、さまざまなアプローチの実現可能性を示唆するものであったが、いずれもルールベースであるという共通の弱点があった。これらのルールは、自動学習を行わず、手作業で記述する必要があった。
つまり、単純な言語構造を持つ文しか扱えず、英語に限定され、より複雑な文には複数のルールを更新する多大な労力を必要とするため、拡張性がなかった。また、文レベルの言語現象を追加で表現するためにスキーマを選択すると、既存のルールの効果を壊してしまう可能性があり、文全体の関係性を考慮したルールになっていないことも意味していました。
これらの限界を超え、ほとんどの文レベルの言語現象を表現できるほど豊富な知識表現への頑健なマッピングを実現するために、我々はロジバン言語と関連リソースを使用することを選択した。
ロジバンは、述語論理に着想を得た形式文法を持つ構築言語である。形式文法のため、いくつかの統制された自然言語と同様の構文的な曖昧さのない表現が可能である。しかし、それらとは異なり、根源的な自然言語の言語現象やそれに伴う表現可能な意味論の限界に制約されることはない。そのため、様々な自然言語に存在する多様な日常的意味構成を伝えることが可能である。
ロジバンは、既知の形式文法(教師なし言語学習が学習しようとするリンク文法や誘導文法のようなもの)と、曖昧さのない知識表現のための丈夫な種を持つ自然言語を提供するものである。ロジバンのプロジェクトは、以下のような問いに答えることを目的としています。
● 与えられた文の中の概念間の意味関係を抽出するルールをどのように生成すればよいのか。
● これらのルールを使って、意味関係から自然言語を生成するにはどうしたらいいか。
● 比較的単純な言語構造を含むロジバン・英語ペアのパラレルコーパスからこれらのルールを学習するプロセスは、より複雑な言語構造にどのようにスケールアップできるのだろうか。
5.2.5.1 ルール学習
本システムは、自然言語(まずは英語)の意味論とロジバンのOpenCog表現を対応付けるルールを学習することを目的としている。これは、ロジバン-英語の翻訳コーパスを用いて行われる。ロジバンの文は、英語訳のリンク文法パースと一緒にOpenCog AtomSpaceにパースされます。そして、リンク文解析に含まれる頻出パターンや意外なパターンをマイニングする。次に、頻出パターンや意外なパターンを持つ英文に対応するロジバン解析が行われる。これらからマイニングされたパターンはロジバンの解析は、英語文のパターンとともに、英語から意味情報を抽出する新たなルールを形成する。
理論的には、複数の文にまたがる意味情報を抽出するルールを学習することができるはずである。例えば、「海の中、日陰のタコの庭にいたい。嵐の下でも暖かい、波の下の小さな隠れ家で」という入力があった場合、このアプローチでは、最後の文の「小さな隠れ家」が、最初の文の「タコの庭」であると理解できるはずである。そのためには、ロジバンの段落全体を英語の段落に翻訳したサンプルを集めた学習コーパスが必要である。文の集合の中から頻出パターンや意外なパターンを探すのではなく、段落の集合全体からパターンを探すことになる。
5.2.5.2 自然言語の生成に貢献
確率論的論理回路網、セマンティックビジョン、その他の処理によって、自然言語パイプラインから得られたものではない、学習されたルールに関わる新しい知識が生成されることがある。もしシステムがこの情報を人間に伝えなければならないのであれば、自然言語で表現しなければならない。
そのために、学習した統語的意味ルールを使って、情報を自然言語構文表現にマッピングすることができる。これにより、確率的自然言語生成システムが文章を生成する。生成システムは教師なし言語学習で学習した形式文法や、既存のリンク文法辞書に対する確率分布の学習に基づいている。
5.2.5.3 複雑な言語構造へのスケーリング
ロジバン-英語パラレルコーパスは、量、トピックの多様性、表現される言語・意味構造において非常に限定的である。しかし、いくつかの自然言語ペアには、同様の(しばしば悪化した)状況が存在します。教師なし機械翻訳の最近の発展は、この問題の解決に有望な進展を示している。
この開発では、単語埋め込みによる単語単位の翻訳(対訳辞書の学習のため)、各言語の事前学習済み言語モデル、次の反復の前にターゲット言語のモデルを用いて翻訳を修正する再帰的バックトランスレーションプロセスを採用しています。
このアプローチからヒントを得て、ロジバン-英語ペアでは、リンク文法辞書とロジバン-OpenCogパーサーはコーパスから学習した確率分布を持つ言語モデルになります。最後のステップである反復修正逆翻訳では、ルールベースがフレーズテーブルの役割を果たす教師なしPBSMTの構造に類似したルール学習パイプラインを経由するか、ルール学習パイプラインとは独立して実行し、後にルールベースの学習に使用されるコーパスを生成することが可能です。
第一のアプローチは統合的なアプローチであり、反復プロセスにPLNやMOSESを含めることが可能になる。このアプローチの利点と欠点は研究分野である。第二のアプローチはモジュール式であり、ルールベース学習に用いることなく、並列コーパスを生成するものである。
5.2.6 ゴール駆動型対話システム
AlexaやSiriなどの一般消費者向けツールや、様々な企業向けチャットボット、カスタマーサポート用チャットボットなど、近年チャットボットや高度な会話型AIシステムの普及が進んでいます。これらの会話型AIシステムの多くは便利なツールですが、一般的に魅力的な会話のパートナーになりきれず、実用的な目的も達成できないことが多く、ユーザーは他の手段(タイピング、ポイント&クリック、人間との会話)で目的を達成することになります。
会話型AIエージェントを真に役立てるために必要な技術は、言語理解、音声合成・分析、確率的常識推論、人間の感情や心理状態のモデル化などの進歩である。
しかし、会話システムの設計において、より基本的な欠点がある。それは、対話制御を支配する首尾一貫した認知アーキテクチャがないことである。
「お茶はいかがですか “というのは、日常会話によく出てくる簡単な言葉です。しかし、この会話には複雑な世界の理解が必要です。お茶を入れることが自分のできることの一つであること、他の人間がお茶を飲みたがることがあること、ティーポットとティーバッグが近くにあること、その他多くのことを知る必要があるのです。私たちは、対話を生成するAIは、自己、相手、状況のモデルを持ち、自己と相手のモデルに照らして特定の状況において特定の目標を達成したいという欲求を持つべきだと考えています。もしそうでなければ、人間の会話のような豊かさと応答性を欠き、実用上の重要な点でも不足することになるでしょう。
現在、AI対話システムには、ニューラルネットワーク、ルールベースアプローチ、ハイブリッドなどがあり、その機能性は様々である。しかし、これらのシステムは、特定のコーパスで利用可能な言語構造をモデル化し、他のセンサーからの入力をあまり考慮せず、対話の文脈の全体的な認知モデリングにあまり焦点を当てずに、発言した内容から意図を抽出することに主に焦点を当てている。
このアプローチは、カスタマーサービスアシスタントや、単一ドメインに限定され、一人の個人と対話する簡単な質問応答システムを構築するのに十分かもしれない。会話の幅や深さを制限することで、そのようなシステムをより簡単に構築し、維持することが可能になるのです。
一方、SingularityNETの会話AIチームは、複数のドメインやグループでの会話を扱い、複数の感覚入力と関連モデルを考慮し、開発者・作者がエージェントを構築・維持する上で喜ばしい対話システムの構築に主眼を置いてきました。この研究は、ハンソン・ロボティクスのハンソンAIチームと共同で行われており、ソフィアや他のハンソン・ロボットのためのリアルな対話システムが重要なアプリケーションの一つとなっています。
これらのチームは、これらの課題の解決策として、OpenCogをベースにしたフレームワークであるGHOST(general holistic organism scripting tool)の開発を進めています。現在、Sophiaをはじめとするハンソン社のロボットが、GHOSTを社会的ロボティクスに応用するためのテストを行っています。
GHOSTは、文脈、行動、行動によって影響を受ける目標の関係をモデル化し、あらかじめ指定された効用関数を満たす行動を選択するためのフレームワークであるOpenPsiをベースにしています。その結果、GHOSTは複数の感覚入力を考慮して意図を抽出し、状況について抽象的な推論を行い、指定された目標によって駆動することができます。
GHOSTベースの対話システムにおいて、すべては高レベルのシステム目標から始まり、次に明示的に指定されるか、システムによって学習されるサブゴールへと続きます。認知的アルゴリズム、そして、言語的入力とその他の感覚的入力や推論といった複数の入力を統合し、現在の文脈の重要な特徴を特定するために使用される。次にシステムは、観測され推論された文脈から、目標達成を最大化することが期待される行動を選択する。これは、発話行動であるかもしれないし、ロボットの場合の動作、オンラインパーソナルアシスタントの場合のメッセージング行動など、他のタイプの行動であるかもしれない。
このように、会話のギブアンドテイクは、より広い認知的文脈に組み込まれ、目標志向と文脈分析・推論が会話の流れの基礎となるのです。
5.2.6.1 意図的な分類
発話の意図を抽出するためには、より広い会話の機能としての文の意味論を理解する必要があります。これは既存のツールでもある程度可能ですが、SingularityNETの自然言語研究チームの研究により、言語構造から抽出できる意図の幅と深さが広がると期待されています。
自然言語処理で得られた信号を増幅するために、聴覚と視覚の入力を統合することを検討する。そのためには、物理的な世界と社会的な世界の相互作用のモデルを明確にする必要があります。
5.2.6.2 対話の表現と状態の追跡
GHOSTは、OpenCogの「経済的注意の割り当て」フレームワークであるECANを使用して、特定のコンテキストで何に注意を向けるべきかを決定しています。これにより、GHOSTは複数のドメインを扱うことができ、開発者や対話の作者はドメイン間のもろい会話フローを指定する必要がありません。この機能は現在活発に開発されています。
現在のGHOSTシステムは、あらかじめ指定された会話領域間の遷移を行うことができますが、その遷移を追跡することは得意ではありません。この遷移をどのように表現すれば、対話状態の追跡が可能になるのか、現在検討中です。
OpenPsiでは、対話の状態追跡はアクション選択と密接に関係しています。これは、対話システムが、OpenPsiのゴールとその間に定義された関係、そしてアクション選択時に使用される効用関数を用いて会話の流れを指定するためです。
現在の研究のもう一つの柱は、グループ会話における状態を表現・追跡し、それらが時間経過とともにどのように変化していくかを明らかにすることである。
5.2.6.3 オーサリング/開発用インターフェイス
GHOSTを使ったアプリケーションを開発するには、ゴールを選択し、ゴール間の関係をモデル化し、ドメインごとに代替の会話フローを記述する必要があります。ゴールシステムの学習は、現時点ではフォーカスされていませんが、いずれはフォーカスされるでしょう。
今後は、強化学習などの機械学習の手法を用いて、会話の流れの構造の指定を簡略化する方法を検討する予定です。私たちが意図しているのはGHOSTベースの会話インターフェースは、ドメインに特化したGHOSTベースの会話システムまたは汎用的なシステムのどちらかを開発(または教育)する際に使用します。
5.2.7 セマンティックハイパーグラフの分散処理
私たちの研究開発プロジェクトの多くは、OpenCogを基盤としています。OpenCogは、複数のAIアルゴリズムが使用する知識を表現するための共通のフレームワークや、複数のAIアルゴリズムを一緒に実行し、連携して中間表現を共有できる方法など、多くの強みを持っています。
しかし、現在のOpenCogには、運用上の弱点もある。例えば、複数のマシンにまたがる分散処理を活用できるのは、比較的限定的な方法のみです。SingularityNETの分散型フレームワークでOpenCogベースのAIを十分に活用するためには、OpenCogの分散スケーラビリティを向上させる必要があるのです。
ここでの重要な課題は、OpenCogのAtomSpaceハイパーグラフ知識ストアを、分散、堅牢、スケーラブルなアーキテクチャを用いて再設計または再実装することです。これにより、SingularityNET上でサービスを提供しながら、OpenCogが大量のデータを処理する能力を向上させ、その信頼性と効率性を確保することができます。
OpenCogはAtomSpaceを利用して知識ベースを操作し、AIコンポーネント間で共有することで、このベースに同時にアクセスし更新する。つまりAtomSpaceは、AIコンポーネントが情報を収集するために問い合わせを行い、蓄積された知識全体を向上させるために更新する共有データベースのようなものと見ることができる。
現実のAIアプリケーションでは、興味深い結果を得るために必要なデータ量が非常に大きくなる傾向があります。つまり、AIコンポーネントが必要な情報を合理的な時間で収集できるように、AtomSpaceから関連情報を抽出する効率的な検索エンジンが必要なのです。この役割を果たすのが「分散AtomSpace」です。
Distributed AtomSpaceは、AtomSpaceに代わる新しいコンポーネントで(あるいはその下敷きになって)、大規模なOpenCog知識ベースを操作し、同時に動作するAIコンポーネントに効率的なクエリを提供し、OpenCogベースのSingularityNETサービスを確実に実現するものである。
5.2.7.1 分散型AtomSpace×分散型データベース
なぜ既存の分散データベースシステムではなく、分散AtomSpaceを作成するのか?AtomSpaceは、少なくとも3つの要件を同時に満たすDBMSがないため、分散データベース管理システム(DBMS)にのみ依存しながら、すべての拡張性要件を達成することは困難です。
OpenCogの知識表現はリレーショナルデータベース、キーバリューデータベース、あるいはグラフデータベースにはうまく適合しません。OpenCogのノードとリンクの表現をリレーショナルテーブル、キーバリューハッシュ、グラフにマッピングすることは可能ですが、対応するDBMSが使用するインデックス付けメカニズムは、AIコンポーネントが行うタイプのクエリの効率性を阻害してしまいます。某氏つまり、ワイルドカードや統一すべき変数を用いて、与えられたパターンにマッチするサブグラフを検索することである。
並行処理とデータの完全性OpenCogの並行処理は、コンポーネントが同じオブジェクトを操作するような論理レベル、あるいは2つのコンポーネントが同じ知識ベース要素(例えば、コンセプト)を操作するような意味レベルで発生します。
この場合、データの完全性ポリシーは、完全性とパフォーマンスの間の設定可能なトレードオフを管理する必要があります。言い換えれば、データの完全性ポリシーは、一方では、各コンポーネントが他のコンポーネントが概念に加えた変更を確実に見ること、他方では、各コンポーネントが遅延なく概念のプロパティを変更できるようにすることのバランスを取る必要があります。
2つ以上のコンポーネントによって同時に変更された概念のプロパティの値を決定することは、簡単なことではありません。この操作(OpenCogでは “マージ “と呼ばれる)は、副作用(知識ベースの他の要素の連鎖的な変更)を伴う複雑な手順を必要とし、関係する概念の種類によって異なる可能性があります。
リファレンスのデータベース管理システムは、キャッシュやロードバランス・ポリシーを実装するために、特定の局所性の定義を使用します。既存のシステムは、局所性が時間的、空間的、または他のいくつかのタイプのうちの1つであると仮定しています。
いずれもOpenCogの知識ベースには適していません。OpenCogに適切なキャッシュ階層とロードバランスポリシーは、コンテキストに応じた局所性によって駆動されなければなりません。この種の局所性は、与えられたコンテキストで意味的に関連する知識ベース要素をまとめておく傾向があります。
例えば、2つのAIコンポーネントC1、C2を考えてみましょう。C1は自然言語のテキストを処理し、C2は空間-時間マップを分析する。どちらのAIコンポーネントも、”数字 “を表す知識ベース要素にアクセスする必要がある。
C1では、与えられた “番号 “に関連する “語彙カテゴリー “を表す要素はすべて関連性があり、近くに置いておく必要があります。C2にとって、「語彙的カテゴリー」を表す要素は全く無関係である。C1とC2が同じ知識ベースで動作している場合、例えばC1とC2の両方がロボットの制御を助けている場合、キャッシュ階層ポリシーは、要素がキャッシュ階層内でどのように移動すべきかを決定するために異なるコンテキストを考慮する必要があります。
5.2.7.2 分散型DBMSの拡張
私たちが分散AtomSpaceプロジェクトで取っているアプローチは、分散DBMSと、上記の問題を軽減する他のカスタムコンポーネントを組み込んだハイブリッドソリューションです。これは下図のように表現されます。
図14 分散型AtomSpaceの構成要素分散型AtomSpaceの構成要素
AIコンポーネントは、通常のAtomSpaceと同じようにDistributed AtomSpaceにアクセスするためのAPIを使用する。ただし、分散DBMS(階層型キャッシュとロードバランサを持つ)を用いてスケーラビリティを実現している。
パターンインデックスは、パターンマッチングのためのクエリーを可能にする検索エンジンです。効率的な検索を行うために転置インデックスを使用する。インデックス自体は永続化される必要があり、これは前述したDBMSを使ってもいいし、使わなくてもいい。
Atom DBとAtomSpaceがキャッシュの階層を形成する。AI Componentはパターンを使ってどの要素の関係が関連するかを定義し、このコンテキスト情報を提供してキャッシュ・ポリシーを駆動する。
SingularityNETの測定、モデル化、拡張
SingularityNETは、様々なタイプのAIアルゴリズムとシステムをホストするためのプラットフォームとフレームワークです。あるものは個々のSingularityNETエージェントの中に住み、またあるものは複数のエージェントに分散して存在します。
しかし、SingularityNETの分散型AIネットワーク全体は、ネットワーク内の個々のAIエージェントが、それ自体が一種のまとまった「心の社会と経済」の下位構成要素である、それ自体が全体的なAIシステムであると考えることもできます。
この分散型ネットワーク知能を実現するためには、複雑な自己組織化ネットワークにおける知能を分析・測定するための手法が必要です。OpenCogのパターンマイニングや推論エンジンのような一般的なAIツールはこの目的に使用できますが、ネットワークの知性を理解することを明確に指向したAIツールや関連ツールも必要とされています。
また、SingularityNETの基盤となる交換やサービス発見のメカニズムに改良を加えることで、SingularityNETの知性と効率を高めることができる可能性も大いにあります。しかし、そのような改良を効果的に探るには、複雑なネットワークを研究するための質の高いツールが必要です。
この研究開発の側面は、ネットワークに様々な作者のAIエージェントが豊富に集まり、この複雑なネットワークの解析と調整が特定のAIツールによって満たされるべき課題となるにつれ、強化されることが予想される。
6.1 記号的相互作用に基づく複雑ネットワークシミュレーションモデリング
初期段階では、SingularityNET上のAIエージェント間の相互作用のネットワークはそれほど複雑ではなく、ネットワークのダイナミクスを分析し規制するのは簡単です。しかし、エージェントの集団がより複雑になり、他のエージェントに複雑なパターンで仕事を委託するエージェントが増えるにつれ、ネットワークの理解、制御、継続的な設計が重要かつ魅力的な課題となってきます。
このような複雑なネットワークを理解し、管理するためには、基本的にシミュレーション・モデリングが唯一の方法となります。この目的のために、SingularityNETの研究者であるDebbie Duong博士は、成熟したSingularityNET内で発生する複雑な経済・認知ダイナミクスをモデル化できるシミュレーション・エンジンの開発を主導しています。このシミュレーションの枠組みを使った実験は、現在、SingularityNETの科学者であるAnton Kolonin博士が設計したSingularityNET adaptive reputation systemの側面に焦点を当てて行われています。
SingularityNETシミュレーションのフレームワークは、社会・経済理論に基づき設計されており、共進化する自律エージェントの心の中で進化的アルゴリズムとニューラルネットワークを使用することができます。シミュレーションの中のエージェントは、タスクをこなし、コミュニケーションをとり、市場で互いに雇い合うことで、社会制度を形成していきます。
このフレームワークはミクロとマクロの統合をサポートし、社会心理学とミクロの社会学から生まれる社会的役割と制度のシステムをモデル化するように設計されています。モデル化される下位レベルの現象としては、象徴的相互作用論(社会学から)、認知的不協和(心理学から)などがある。同時に、ゲーム理論の効用追求行動から市場制度が生まれるなど、経済学におけるミクロ-マクロ統合のモデル化も行っている。
このシミュレーションの初期の実験では,偏見と人種差別,ステータスシンボル,社会階級,役割に基づく分業,価格,貿易基準(貨幣),腐敗文化,政治的偏向,市場,競争相手の生態系をモデル化している.この予備的な研究により、シミュレーションのフレームワークが社会、経済、文化のあらゆる現象を包含できることが示された。これは、成熟したSingularityNETが、外部の多様な人間システムや計算機システムと結合したときに、どのような種類のダイナミクスが生じるかを予測することが困難であるため、不可欠なことです。
SingularityNETのシミュレーションフレームワークの設計で重要なのは、分散化の主要な要素である「自律性」です。この自律性には、行動の自律性(エージェントが適切と考える効用を実現する能力)だけでなく、知覚の自律性(エージェントが効用を実現する方法で、コミュニケーションを含む環境を自由に解釈する能力)も含まれます。
多くの共進化システムとは異なり、我々のアプローチでは、エージェント集団の適性はエージェント間で平均化されることはない。むしろ、エージェントは個人的な効用を追求するのみである。エージェントは互いに信号を送ることができ、その信号を解釈する知覚の自律性を持っているので、自分のニーズを満たすために他のエージェントを分類し契約することを学習する。
このシミュレーションでは、エージェントは他のエージェントを、自分が役に立つと思うグループ分けに割り当てる。このようなグループ分けは、エージェントが他のエージェントを見つけるのに役立ち、グループ分けに関する信念を共有することが有利であるとエージェントが判断すると、グループ分けは最終的に制度化された役割となる。エージェントは、グループとして単独よりも大きな圧力をかけることができる。例えば、自然な顧客のグループとある製品タイプの生産者のグループを考えてみよう。
象徴的相互作用論の理論と同様に、主体は、他者が自分について抱いている信念に従って行動することが有利であることを見出す。このような自己組織化された集団が、社会的役割と制度である。これらは、ミクロレベルの効用追求型の象徴的相互作用論から生まれてくる。したがって、エージェントは、多くの協力的共進化プログラムのようにグループに「割り当てられる」のではなく、むしろ、グループは効用を求める相互作用から出現する。
我々のミクロ-マクロ統合と創発のプロセスは、協調的共進化的適性の平均化技法を改良したものである。これらの技術では、信用を割り当てることはしない(これはグループ内のエージェントが他のグループで同様の役割を担う能力を制限することになる)。我々のシステムでは、信用を割り当てることで、エージェント間のフィードバックが価格シグナルを通して行われる。価格シグナルを通じて、異なる知能を持つエージェントは、他者にとって最も価値のある役割を担うよう動機付けされるのである。エージェントの文化は発展し、個々のエージェントの寿命を超えて存続します。古いAIは、新しいAIに、この自己組織化されたシステムにおいて最も有利な役割を与えるよう導く。
この一般的なシミュレーション手法は、Duong博士のこれまでの研究において様々な形で活用されており、「貿易と創発的役割の象徴的相互作用論的シミュレーション(SISTER)」と名付けられています。SingularityNETの初期の研究において、私たちはSISTERを実際の社会のモデル化(社会政策のテスト)や人工社会におけるAIシステムの生成に用いてきました。
6.1.1 模擬ネットワークにおけるエージェント選択
現在、私たちはSISTERを応用して、能力の異なる多様なAIが自己組織化して問題を解決することを支援しています。これらのAIは、現在のAIアンサンブルよりも複雑な方法で協力し、競争します。
SISTERは、エージェントが創発システムにおける自分の役割を学習するための意味空間を作り出します。SingularityNETのシミュレーションでは、様々なAIが集まって、Pythonプログラムを選択し、パラメータ化し、組み立てるという問題を解決しています。
現在、各SISTERエージェントのAIとしてCMA-ESを使用していますが、スカラーまたは離散的なAI手法は、どのようなエージェントの組み合わせでも使用できます。エージェントが他のエージェントに入札するための黒板(グローバルまたはローカルのどちらでも可)があります。お客さまは、ご自分のお客様は、どのサプライヤーが良いサービスを提供しているかという過去の経験をもとに、サプライヤーを選択することができます。また、顧客はサプライヤーの価格に関する基準も学んでいる。最後に、次節で述べるように、サプライヤーが示す「看板」についての基準がある。
6.1.1.1 SISTERシステムにおけるAIエージェントの標識
符号には、浮動小数点数のベクトル、または0と1の文字列を使用することができます。この記号は、最初は何も意味しないが、エージェントが顧客の成功のためにより成功するようになると、自分自身を識別するために使うことを学ぶ。そうすることで、この記号は暗黙の要件の集合を意味するようになる。
記号が意味を持つようになり、エージェントがユースケースを解決できるタイプにグループ化される過程は以下の通りである。
シミュレーションの最初(エージェントが何も学習していない状態)では、顧客(Carl)はデータセットをクラスタリングする「クラスタリング」サービスを探しています。カールはクラスターがシルエット・テストに合格することを要求し、23 AGIトークン以下の値段でそれを受けることになる。彼はまだどのようなサインを探せばよいかを学んでいないので、彼はサインのランダムな要求を生成する。
ネットワーク上の2つのクラスターがカールのテストに合格し、AGI23以下の価格を持っている。そのうちの1つ(クロエと呼ぶ)は、偶然にもカールが求める任意の符号に近い符号を持っている。カールはクロエのサービスを利用し、両者ともネットワーク上の効用を向上させる。こうして、Carlは次にクラスタラーを雇いたいときには似たような標識を探すことを(強化によって)学習する。Chloë The Clustererは、そのクラスター・サービスのためにそのような看板を表示することを学習する。顧客が看板を探しているので、その看板を掲示している他のエージェントが取引に来ることができる。こうして、看板は “クラスター屋 “を意味するようになる。
ここで、クロエが別のサービス、ベクトル空間作成者のビクターと下請け契約しているとしよう。この場合、ビクターは、誰かがクロエを雇った場合にのみお金を得ることができる。そうすると、ベクトル空間クリエイターがクラスターのお客さんに見せる看板は、”シルエットテストに合格するのを手伝いますよ “という意味になるんです。
しかし、Victor The Vector-Space Creatorの顧客はChloëだけではありません。ビクターは、クロードという名前の別のクラスターにもサービスを売っている。クロードは、シルエットテストで採用されたわけではなく、あるデータセットにうまくフィットするモデルを作ることを命じられたモリーによって採用されたのだ。
つまり、ビクターのサインは、クロード・クラスターを助けることによって、モリーのモデルをデータに適合させるのを助けることができるという意味もあるのです。ビクターのサインは、競争相手の能力を考慮した上で、有用性をもたらす特定の、出現したユースケースの集合を助けることができることを意味します。
ここで、このシミュレーションに新しいエージェントが登場し、「クラスタリング」サービスを提供できることを示すサインを表示したとする。このエージェントは、無数の要求を満たすための要求を受け取り、また、ネットワークがクラスターがベクトル空間クリエイターのサービスを必要とすることを学習したため、ベクトル空間クリエイターからオファーを受けることになる。もしエージェントが効果的にサービスを提供できれば、その看板を表示し続けるよう選択的な圧力を受けることになる。もし、そのエージェントが前任者よりも良い仕事をすることができれば、ベクトル空間クリエイターのサービスを買わずに、顧客を喜ばせるために他のものを買うかもしれない。もし、先行者よりも良い仕事ができないのであれば、より能力のあるものを示す別の標識を表示するよう選択的圧力を受ける。
SISTERシステムでは、標識は類似の要求とその典型的な実装の効用空間を形成する。シミュレーションが進むにつれ、エージェントは有能になり、競争システムが発展し、テストのしきい値が上がり、より多くのテストが必要となり、価格のしきい値が上がり、標識は次のようなものになる。
教師なし手法(クラスタリングなど)のテストは弱いですが、顧客のグループ、その顧客のグループなど、複数の弱いテストの集合的な効果が、パフォーマンスを形成するのに有効です。
6.1.2 社会問題を解決するソーシャルアルゴリズム
米国政府機関向けにSISTERを適用した先行研究では、共進化AIを利用して社会問題の解決に貢献しました。私たちの研究の1つのラインは、偏見やステレオタイプの起源を理解し、政策的な手段で問題を軽減する方法を理解することです。
リカレントニューラルネットワークを心として持つエージェントを用いて、異なる民族や性別の人々が、内面的には同等の才能を持っているにもかかわらず、制度的に誤解され、才能を発揮できない社会的役割を強いられることをシミュレートしているのです。
また、ある固定観念の階級の人を過大評価し、別の固定観念の階級の人を過小評価するPageRankのようなソーシャルメディアのアルゴリズムについても研究している。これがどのように社会階級と寡頭政治を形成するか、また、より公正であるばかりでなく、ほとんどすべての利害関係者にとってより良い実用性をもたらす代替的なソーシャルメディアアルゴリズムについて見ている。
次に、偏見や寡頭政治に対するデジタルの保護について分析します。ソーシャルメディアにはない自然な社会的保護が、心理的操作に対する脆弱性をもたらすことに注目する。特に、エージェントマインドにリカレントニューラルネットワークで実装された心理的認知的不協和のモデルを通して、情報戦争とその集団への影響について研究している。社会全体における政治的偏向の発達を示し、情報戦の影響下にない場合の中央値投票者の定理に基づくものなど、より標準的な政治モデルと比較する。
このモデルをもとに、格差是正のための政策を検証する。我々は、社会制度のソフトな均衡と、社会制度を弱体化させるハイブリッド戦争戦術によって腐敗がどのように社会全体に広がるかを見ている。このような戦術が個人に与える影響と、その結果生じる崩壊から社会がどのように回復するかを検証する。
ここで重要なのは、私たちが実際の人間社会でモデル化した現象の多くが、成熟したSingularityNETネットワークでも起こることが予想される点です。寡頭制の形成、ステレオタイプによるエージェントのクラスの過大評価、腐敗と偏向の出現などは、人間社会と同様にAIエージェントシステムでも起こりうる現象です。
大規模なSingularityNETを十分に機能させるためには、このような現象が蔓延しないように、適切なシミュレーションモデルを使って実験し、発生する条件や対策方法を理解することが一番です。
このようなモデリングを実世界の状況(人間またはAIエージェント)にきめ細かく適用するには、実世界のデータを使ってシミュレーションの重要な側面を条件付ける必要があります。我々は、社会環境をモデルに取り込むための3つの方法を提案します。
一つは、観測データから政策の効果を原因を探る形でマルコフ決定過程を作成することである。マルコフ決定過程の因果関係が正しく入力されるように、道具変数、Pearlの「do」、潜在的な結果のフレームワークを使用します。次に、複雑なシステムでは、データを直接入れるだけではダメで、フィードバック、ネットワーク効果、相互の因果関係によって観測データが作られていることを認識します。そこで、共進化のツールを使い、複数のモデルでデータをシミュレーションすることで、観測データに見られる好循環と悪循環を再現しています。
最後に、シミュレーションのオントロジーにデータを取り込むことが困難な場合がある(特にフリーテキストデータの場合)。我々は、モデルと同じオントロジーにクラスタリング装置をシードするために、わずかな模範解答があればよい共進化に基づくクラスタリング技術を提供する。
6.2 複雑な認知ネットワークの統合情報を測定するためのTononi Phi
複雑な認知AIシステムの全体的な状態を測定・分析することは困難です。私たちは現在、SingularityNET自体やAIフレームワークOpenCog、Hanson Robotics社の人型ロボットSophiaなど、さまざまな複雑なAIネットワークにおける「統合情報」の全体レベルを測定するツールとして、Tononi Phi係数を実験している。
2004年、ウィスコンシン大学の精神科医で神経科学者のジュリオ・トノーニは、意識を研究し定量化するための詳細かつ発展的なシステムと計算法を考案し、「統合情報理論(IIT)」と名付けた。このフレームワークで定義されたPhi係数は、システムにおける全体的な情報統合のレベルを測定するものである。トノーニ(Giulio Tononi)らによって、Phiは「意識レベル」の基本的な尺度であると提唱されている。その解釈はともかく、複雑な認知システムの意識に関連する性質を測る指標としては興味深い。Phiの最大化を目標とすることは、価値ある結果につながるかもしれない。
また、Phiは、複雑な力学系のパラメータを調整し、高度なネットワーク構造の出現を促すフィードバック機構としての可能性も持っています。このように、IITとPhiは、複雑なネットワーク構造を分析し、真のAIベースの社会的・感情的ロボットシステムを開発し、より優れた知的な一般AIサービスを生み出すための新たなツールとして機能することが期待されます。
我々は、OpenCogのECANアテンションアロケーションモジュールが生成した時系列のPhiを、システムが一連の短い文書を解析し意味解析している間に測定する実験を行った。また、OpenCogシステムが人型ロボット「ソフィア」を制御し、構造化された瞑想セッションで人を誘導しながら、Phi値を計算しました。
後者の実験では、計算量の増大による困難さから、独立成分分析(ICA)によるデータの前処理を行い、問題の次元を下げるという新しい手法も実験した。いずれの実験でも、得られたPhi値の時系列と、OpenCogシステムの外部状況や動作におけるイベントの時系列を比較しました。定性的には、Phi値の変化と認知システムの状況・行動の変化との間に対応関係が見られ、本手法の予備的な検証を行うことができた。
IITとPhiの実験を続ける中で、私たちの目標の一つは、より高性能でより知的なAIサービスの開発を導くために、複雑な創発現象を測定するための新たなツールを作り出すことです。IITは、相互接続性を定量化する強固な理論的手法を提供することで、最終的に様々なシステム構成要素の内部と外部の両方における協力関係を改善することにつながります。
6.2.1 チューニングパラメーター
システムの結合度を測る指標として、Phi/IITは多くのAIサービスの基礎となる複雑なネットワーク構造の多くを改善するために使われるでしょう。IITとPhiの測定は、複雑な力学系における多くの自由なシステムパラメータを調整するための追加のフィードバックループを確立することで、より質の高いサービスに貢献することができます。下図は、ECANモジュールにおける代表的なフィードバックループを示したものである。PLN、MOSES、その他のツールにも同様の図があるはずである。
図 15.ECANモジュールの代表的なフィードバックループ図
6.2.1.1 AIシステムにおける認知的尺度の定量化
認知シナジーの概念は、OpenCog AIフレームワークの中心的なものである。我々は、IITとPhiの測定をより大きなスケールの構造に適用し、モジュール間およびモジュール内のパラメータチューニングを促進します。このような方法でIITを探索することで、多くのモジュール間の相乗効果を生み出すことができます。
OpenCogの主要なモジュールとツールは、より包括的で基本的により頑健な(すなわち「行き詰まり」を克服できる)一般的な問題解決へのアプローチを可能にします。私たちが実験するOpenCogのモジュールとツールは以下の通りです。
● PLN.確率論的論理回路網形式における前方連鎖と後方連鎖に基づく確率論的論理回路網エンジン
● MOSESルールベースのプログラム正規化、確率的モデリングなどの高度な機能を組み込んだ進化型プログラム学習フレームワーク
● ECANShortTermImportanceとLongTermImportanceの値の広がりに応じて注意を割り当てる非線形力学とヘブ型学習に基づく “経済的注意配分 “エンジン
● パターンマイニング情報理論に基づく貪欲な超グラフパターンマイニング
● 既存の概念ノードから新しい概念ノードを形成するためのクラスタリングと概念ブレンドのヒューリスティック。
Phi値が高いほど、そのようなシステムから生じる興味深い認知行動と相関があるはずである(初期の実験では、このことが示唆されている)。システム接続性」のPhi測定は、例えば、異なるネットワーク下部構造、モジュール、およびツール間の相乗効果を定量化することにより、サービスを向上させることができる。
6.2.2 特異なSingularityNETサービスに対する影響
社会的・感情的なロボティクスにおいて、PhiはSophiaの瞑想セッション中の質的に興味深い行動と相関していることが予備的な実証実験から示唆されています。今後、ハンソン・ロボティクス社やアイ・コンシャス社などとの共同プロジェクト「Loving AI」において、PhiとSophiaの知覚や行動の関係をさらに研究していく予定であり、人間に対して無条件の愛を表現するロボットやアバターの制作を目指す。人間とロボットの対話中にPhiを測定することで、顔の表情や動作、言語理解や音声合成の向上も期待できる。
システムの性能とインテリジェンスを(個々のコンポーネント内とコンポーネント間の相乗効果によって)向上させることができれば、ネットワーク分析、ソーシャルロボティクス、バイオデータ分析など、さまざまな領域でSingularityNETサービスの向上につながるはずです。
具体的には、ネットワーク解析の分野では、パラメータチューニングの向上に加え、全体的なファイの測定が可能です。
● Phi固有の因果関係のレパートリーの結果、ソーシャルネットワーク分析および可視化、確率的グラフィカルモデリングのための因果関係の測定値を向上させることができます。
● は、システム現象が単純なルールからどの程度生まれるかを定量的に把握するのに役立つ。
● ネットワーク化された人工知能における、分散したAIプログラム間の協調的・競争的なつながりと、これらのアルゴリズムが自己組織化してより良い解決策を生み出すプロセスの研究を向上させること。
● システムの統合的なつながりを定量化し、認知的シナジーを向上させることで、実世界のシステムにおける好悪のフィードバックサイクルの研究を支援し、最終的に目標達成のための最適なポリシーを見出すことを支援します。
6.3 エージェントシステムにおける複雑な交換パターンを最適化するためのオファーネットワーク
オファーネットは、多様で独立した相互作用するエージェントによって駆動される根本的に分散化された経済の実現を目指した研究イニシアチブです。これは、密接に関連しながらも異なる抽象度を持つ2つの研究開発経路を組み合わせたものです。
● 異種プロセスの非同期実行をサポートし、異種プロセス間の創発的協調と制御的協調の混合をモデル化できる大規模スケーラブルコンピューティングモデルとソフトウェアフレームワークです。7
● 純粋な通貨ベースの交換に代わる分散型経済。この経済は、複雑な相互作用のネットワークを特徴とし、互換性と補完性のある選好を持つエージェントを見つけ出し、その相互作用を調整することによって、財とサービスの相互交換を最適化する。7
B)の研究開発は(A)に決定的に依存していますが、(A)の重要性と応用範囲は(B)よりもはるかに広いのです。つまり、我々は、オファーネット経済への応用を越えて、最大限の水平スケーラビリティを持つ分散コンピューティングとシミュレーション・モデリング・プラットフォームを設計しているのです。
6.3.1 分散型コンピューティング
オープンエンド型分散コンピューティングのコンセプトは、OfferNets研究イニシアティブの中で開発されています。これは、異種非同期プロセスが、共有トポロジカル空間を介した間接的な通信によって、自発的または誘導的な互換性を達成することを可能にするものです。
このモデルの目的は、経済、統治体制と構造の異なる組み合わせ、複数の通貨、物々交換ネットワークなどを含む分散システムの大規模なシミュレーションを作成することです。このモデルは本質的に分散型であるにもかかわらず、さまざまなレベルの中央集権化を実現することが可能です。
6.3.2 シミュレーションエンジン
OfferNetsのシミュレーションが実行されるソフトウェア・アーキテクチャは、大きく2つの部分から構成されています。
● メッセージパッシングによる異種エージェントロジックの非同期実行とピアツーピアのインタラクションを実現するアクターフレームワーク 7
● ネットワークのトポロジー情報を保持・更新し、間接通信を可能にするエンタープライズレベルのグラフデータベースサーバーを搭載
6.3.3 監視・分析エンジン
シミュレーション・モデリングには、システムで起きている事象に関する情報を収集し、分析することが必要です。分散型アプリケーションフレームワークは、定義上、システムへのアクセスポイントが1つではないため、多くのソースから来る大量のストリーミングデータを収集し、処理するための専用エンジンを構築しました。
エンジンの基本原理は、各エージェントに代わって監視メッセージを発行し、それらを単一の(ただし分散された)データベースにキャッシュしインデックスを作成することです。このエンジンの技術的な基盤は、ストリーミングデータの管理と分析を統合したソリューションであるElasticStackです。
モニタリングパイプラインは完全に分散化されており、複数のマシンに拡張可能で、各コンポーネントの故障や再起動にも耐性があります。同様に、シミュレーションエンジンも、シミュレーションや本番環境での必要な負荷に応じて、複数のマシンに容易に拡張することができます。どちらも、Webフロントエンドを介して、すべてのマシンをリアルタイムで監視することができます。ネットワークやエージェントの活動をリアルタイムで監視し、イベントを取得することは、インフラストラクチャの他の部分からのデータストリームを受け入れるカスタムWebフロントエンドを介して利用可能です。
6.3.4 オファーネッツ エコノミー
分散コンピューティングモデルとアーキテクチャにより、エコシステム内で直接または間接的に相互作用し調整する、実質的に制約のない数の計算プロセスを実装、テスト、展開し、その進化を観察することができるようになりました。課題は、具体的なプロセスを定義し、それらの相互作用を設計し、望ましいダイナミクスに向けてオファーネットエコノミーを微調整することです。
つまり,ノードの種類とそのプロパティ,エッジの種類とそのプロパティ,グラフの走査と突然変異の制約を定義するプロセスで形式化されています.ネットワーク上で動作するすべてのエージェントは、任意のプロセスを実装することができる。OfferNetsのソーシャルグラフとのインタラクションを必要とする処理は,グラフ・トラバーサルとして実装されます.それ以外の処理は,従来の非同期アルゴリズムとして表現されます.現在,OfferNetsでは,基本的な類似性検索処理とサイクル検索処理を実装しています.サイクル実行処理と高度な検索処理については,現在パイプラインで開発中です.
オファーネットに関する計算実験の構想、実装、実行、そしてモニタリングエンジンが収集したデータの解析は、意味のある探索を行うために必要なパラメータ空間が大きく、多くの繰り返しが必要なため、計算量が多くなります。
さらに、シミュレーションを行うたびに新たな疑問が生まれ、次のシミュレーションの設定に反映されるという意味で、オープンエンドなプロセスであると言えます。計算基盤もドメインモデルも、繰り返し行うたびに変化し、改善されていきます。2018年8月のシミュレーション・モデリング実験開始以来、同じグラフ構造上で集中型と分散型の探索アルゴリズムを比較するシミュレーションを実施しています。
6.3.5 SingularityNETのメインネットワークへの統合
OfferNetsの研究イニシアチブは、SingularityNETの分散型AIネットワークの開発にいくつかの異なる方法で貢献すると推定されます。具体的な手段や統合の範囲は、以下の可能性からベータ版ローンチ後に決定されます。
● SingularityNETネットワークの上で、AIエージェントによる自動分散型マーケットプレイスとエコノミーを開発する。OfferNetsは、プロセスを入出力によって連鎖させる汎用的な分散型メカニズムを提供しているため、SingularityNETのAIエージェント間で自動的にワークフローを構築する仕組みを研究するための基盤となる可能性があります。7
● レピュテーションシステムのシミュレーションを含む、SingularityNETベータ版の上での大規模なシミュレーションとテスト。OfferNetsでは、SingulartyNETのインフラをgRPC APIで呼び出すような、異なる振る舞いをするAIサービスプロバイダのシミュレーションを構築し、SingularityNETのベータ版インフラの上でシミュレーションを実行することが可能です。7
● SingularityNETでの実装のために、分散型ネットワークの運用とガバナンスに関する概念的および計算論的洞察を提供する。OfferNetsは根本的に分散化された設計思想に従っていますが、現実世界のシステムはしばしば中央集権と分散化の健全なバランスを必要とします。研究環境において分散化の限界に挑戦することで、現実的な環境において有用である可能性がありながら、別途テストと実装が必要となる可能性のある洞察を得ることができます。7
● SingularityNETや、場合によってはその先のAIや高度な自律型ロボットの統合能力を最大限に引き出す、新しい分散型経済・社会モデルの概念研究とシミュレーション・モデリングをさらに進める。
この方法は、新しい経済的・社会的ガバナンスのアイデアに取り組んでいる既存のシンクタンクとのパートナーシップを含むように拡張することができます。
乳幼児期から児童期、そしてその後までネットワークを導く
SingularityNETプラットフォームの仕様、ネットワーク上で利用可能なAIアルゴリズムとサービスの集合体は、エコシステムのニーズとコミュニティの貢献に基づいて、アジャイルに進化し適応することを意図しています。このプロジェクトの成功には、このホワイトペーパーで紹介した資料のかなりの部分が急速に陳腐化することが予想されます。
しかし、SingularityNETの設計の精神は、成長と変化に対して頑健であることを意図しています。相互運用し、価値を交換するAIが、民主的かつ分散的な方法で制御され、自ら顧客にサービスを提供し、その知能が部分の知能の総和を超えるサブネットワークに連動するというコンセプトは重要で、プロジェクトの創設者とそれを指導するSingularityNET財団が、プロトコル、アルゴリズム、構造、標準の細部が成熟しても続いて欲しいと願うものであり、これこそが鍵となります。
SingularityNETのようなプロジェクトのこのダイナミックな側面の帰結は、プロジェクトに対するコミュニティの中心性です。開発者、ユーザー、テスター、エバンジェリスト、その他のコミュニティメンバーからなるエコシステムが、プラットフォームとそれがサポートするAIの継続的な成長と変化を推進するのです。
ベータ版のリリースにより、SingularityNETは幼年期を超えましたが、まだ幼年期のごく一部に過ぎません。この萌芽期において、ネットワークの成長は、ネットワークに関わる人間とAI双方の情報、情熱、価値の交換によって、パワーアップし、導かれることになります。

